javascript
# 1. Mouseenter 和 Mouseover 的区别
mouseover 事件:不论鼠标指针穿过被选元素或其子元素,都会触发 mouseover 事件。
mouseenter 事件:只有在鼠标指针穿过被选元素时,才会触发 mouseenter 事件。
以及
mouseout 事件:不论鼠标指针离开被选元素还是任何子元素,都会触发 mouseout 事件。
mouseleave 事件:只有在鼠标指针离开被选元素时,才会触发 mouseleave 事件。
# 2. alert(1&&2),alert(1||0)
&&运算符,前面的 true,返回后面的。前面的为 false,返回前面的。
||运算符,前面的为 true,返回前面的。前面的为 false,返回后面的。
# 3. 为什么 TCP 连接需要三次握手,两次不可以吗,为什么
感觉自己还没懂,先占坑,可看知乎
# 4. Js 字符串两边截取空白的 Trim 的原型方法的实现
# 5. ['1', '2', '3'].map(parseInt) What & Why ?
| |
奇怪吧
首先需要知道 parseInt:
parseInt(string, radix) 将一个字符串 string 转换为 radix 进制的整数, radix 为介于 2-36 之间的数。即将 string 看作是 radix 进制的数,并返回其对应的十进制数。
string要被解析的值。如果参数不是一个字符串,则将其转换为字符串 (使用
ToString抽象操作)。字符串开头的空白符将会被忽略。radix一个介于 2 和 36 之间的整数 (数学系统的基础),表示上述字符串的基数。比如参数 10 表示使用十进制数值系统。始终指定此参数可以消除阅读该代码时的困惑并且保证转换结果可预测。当未指定基数时,不同的实现会产生不同的结果,通常认为其值默认为10,但是如果你的代码运行在过时的浏览器中,那么请在使用时总是显式地指定 radix。
返回解析后的整数值(十进制)。 如果被解析参数的第一个字符无法被转化成数值类型,则返回
NaN。
注意:
radix参数为 n 将会把第一个参数看作是一个数的 n 进制表示,而返回的值则是十进制的。例如:
| |
如果
parseInt的字符不是指定基数中的数字,则忽略该字符和所有后续字符,并返回解析到该点的整数值。parseInt将数字截断为整数值。允许使用前导空格和尾随空格。使用 parseInt 去截取包含 e 字符数值部分会造成难以预料的结果。例如:
parseInt(“6.022e23”, 10); // 返回 6
parseInt(6.022e2, 10); // 返回 602在基数为
undefined,或者基数为 0 或者没有指定的情况下,JavaScript 作如下处理:- 如果字符串
string以 “0x” 或者 “0X” 开头, 则基数是 16 (16 进制). - 如果字符串
string以 “0” 开头, 基数是 8(八进制)或者 10(十进制),那么具体是哪个基数由实现环境决定。ECMAScript 5 规定使用 10,但是并不是所有的浏览器都遵循这个规定。因此,永远都要明确给出 radix 参数的值。 - 如果字符串
string以其它任何值开头,则基数是 10 (十进制)。
如果第一个字符不能被转换成数字,
parseInt返回NaN。算术上,
NaN不是任何一个进制下的数。 你可以调用isNaN来判断parseInt是否返回NaN。NaN参与的数学运算其结果总是NaN。将整型数值以特定基数转换成它的字符串值可以使用
intValue.toString(radix).- 如果字符串
其次还得知道 map():map() 方法创建一个新数组,其结果是该数组中的每个元素都调用一个提供的函数后返回的结果。
| |
可以看到
callback回调函数需要三个参数, 我们通常只使用第一个参数 (其他两个参数是可选的)。
currentValue是 callback 数组中正在处理的当前元素。
index可选, 是 callback 数组中正在处理的当前元素的索引。
array可选, 是 callback map 方法被调用的数组。另外还有
thisArg可选, 执行 callback 函数时使用的 this 值。
| |
对于每个迭代 map, parseInt() 传递两个参数: 字符串和基数。 所以实际执行的的代码是:
| |
即返回的值分别为:
| |
所以:
| |
由此,加里·伯恩哈德例子也就很好解释了,这里不再赘述
| |
如下解决
| |
# 6. 防抖与节流
- 防抖
触发高频事件后 n 秒内函数只会执行一次,如果 n 秒内高频事件再次被触发,则重新计算时间
- 思路:
每次触发事件时都取消之前的延时调用方法
| |
- 节流
高频事件触发,但在 n 秒内只会执行一次,所以节流会稀释函数的执行频率
- 思路:
每次触发事件时都判断当前是否有等待执行的延时函数
| |
# 7. 介绍下 Set、Map、WeakSet 和 WeakMap 的区别?
Set 和 Map 主要的应用场景在于 数据重组 和 数据储存
Set 是一种叫做集合的数据结构,Map 是一种叫做字典的数据结构
# 1. 集合(Set)
ES6 新增的一种新的数据结构,类似于数组,但成员是唯一且无序的,没有重复的值。
Set 本身是一种构造函数,用来生成 Set 数据结构。
| |
举个例子:
| |
Set 对象允许你储存任何类型的唯一值,无论是原始值或者是对象引用。
向 Set 加入值的时候,不会发生类型转换,所以 5 和 "5" 是两个不同的值。Set 内部判断两个值是否不同,使用的算法叫做“Same-value-zero equality”,它类似于精确相等运算符(===),主要的区别是**NaN 等于自身,而精确相等运算符认为 NaN 不等于自身。**
| |
Set 实例属性
constructor: 构造函数
size:元素数量
1 2 3 4let set = new Set([1, 2, 3, 2, 1]) console.log(set.length) // undefined console.log(set.size) // 3
Set 实例方法
操作方法
add(value):新增,相当于 array 里的 push
delete(value):存在即删除集合中 value
has(value):判断集合中是否存在 value
clear():清空集合
1 2 3 4 5 6 7let set = new Set() set.add(1).add(2).add(1) set.has(1) // true set.has(3) // false set.delete(1) set.has(1) // falseArray.from方法可以将 Set 结构转为数组1 2 3 4 5 6const items = new Set([1, 2, 3, 2]) const array = Array.from(items) console.log(array) // [1, 2, 3] // 或 const arr = [...items] console.log(arr) // [1, 2, 3]
遍历方法(遍历顺序为插入顺序)
keys():返回一个包含集合中所有键的迭代器
values():返回一个包含集合中所有值得迭代器
entries():返回一个包含 Set 对象中所有元素得键值对迭代器
forEach(callbackFn, thisArg):用于对集合成员执行 callbackFn 操作,如果提供了 thisArg 参数,回调中的 this 会是这个参数,没有返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16let set = new Set([1, 2, 3]) console.log(set.keys()) // SetIterator {1, 2, 3} console.log(set.values()) // SetIterator {1, 2, 3} console.log(set.entries()) // SetIterator {1, 2, 3} for (let item of set.keys()) { console.log(item); } // 1 2 3 for (let item of set.entries()) { console.log(item); } // [1, 1] [2, 2] [3, 3] set.forEach((value, key) => { console.log(key + ' : ' + value) }) // 1 : 1 2 : 2 3 : 3 console.log([...set]) // [1, 2, 3]Set 可默认遍历,默认迭代器生成函数是 values() 方法
1Set.prototype[Symbol.iterator] === Set.prototype.values // true所以, Set 可以使用 map、filter 方法
1 2 3 4 5 6let set = new Set([1, 2, 3]) set = new Set([...set].map(item => item * 2)) console.log([...set]) // [2, 4, 6] set = new Set([...set].filter(item => (item >= 4))) console.log([...set]) //[4, 6]因此,Set 很容易实现交集(Intersect)、并集(Union)、差集(Difference)
1 2 3 4 5 6 7 8 9 10let set1 = new Set([1, 2, 3]) let set2 = new Set([4, 3, 2]) let intersect = new Set([...set1].filter(value => set2.has(value))) let union = new Set([...set1, ...set2]) let difference = new Set([...set1].filter(value => !set2.has(value))) console.log(intersect) // Set {2, 3} console.log(union) // Set {1, 2, 3, 4} console.log(difference) // Set {1}
# 2. WeakSet
WeakSet 对象允许你将弱引用对象储存在一个集合中
WeakSet 与 Set 的区别:
- WeakSet 只能储存对象引用,不能存放值,而 Set 对象都可以
- WeakSet 对象中储存的对象值都是被弱引用的,即垃圾回收机制不考虑 WeakSet 对该对象的应用,如果没有其他的变量或属性引用这个对象值,则这个对象将会被垃圾回收掉(不考虑该对象还存在于 WeakSet 中),所以,WeakSet 对象里有多少个成员元素,取决于垃圾回收机制有没有运行,运行前后成员个数可能不一致,遍历结束之后,有的成员可能取不到了(被垃圾回收了),WeakSet 对象是无法被遍历的(ES6 规定 WeakSet 不可遍历),也没有办法拿到它包含的所有元素
属性:
constructor:构造函数,任何一个具有 Iterable 接口的对象,都可以作参数
1 2 3const arr = [[1, 2], [3, 4]] const weakset = new WeakSet(arr) console.log(weakset)
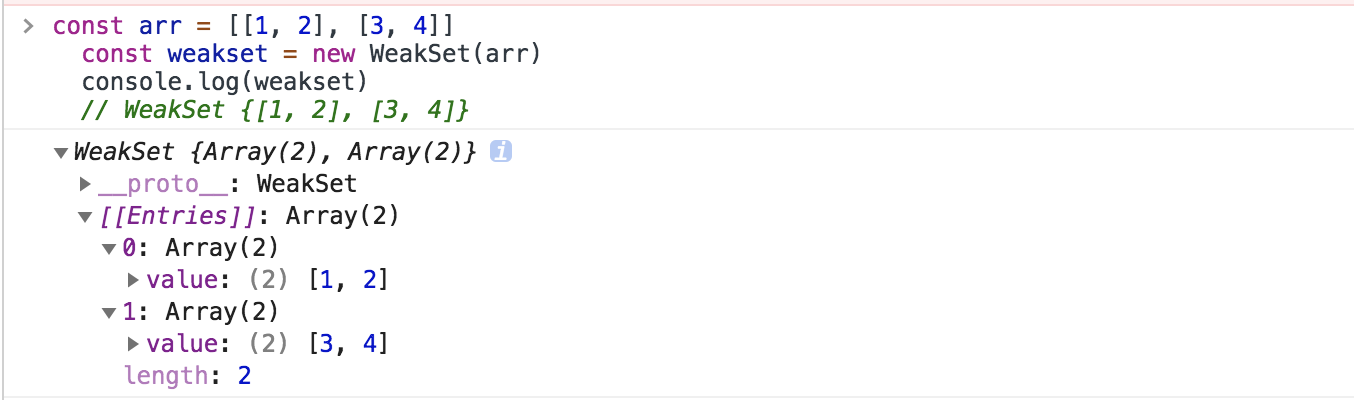
方法:
- add(value):在 WeakSet 对象中添加一个元素 value
- has(value):判断 WeakSet 对象中是否包含 value
- delete(value):删除元素 value
- clear():清空所有元素,注意该方法已废弃
| |
# 3. 字典(Map)
集合 与 字典 的区别:
- 共同点:集合、字典 可以储存不重复的值
- 不同点:集合 是以 [value, value] 的形式储存元素,字典 是以 [key, value] 的形式储存
| |
任何具有 Iterator 接口、且每个成员都是一个双元素的数组的数据结构都可以当作 Map 构造函数的参数,例如:
| |
如果读取一个未知的键,则返回 undefined。
| |
注意,只有对同一个对象的引用,Map 结构才将其视为同一个键。这一点要非常小心。
| |
上面代码的 set 和 get 方法,表面是针对同一个键,但实际上这是两个值,内存地址是不一样的,因此 get 方法无法读取该键,返回 undefined。
由上可知,Map 的键实际上是跟内存地址绑定的,只要内存地址不一样,就视为两个键。这就解决了同名属性碰撞(clash)的问题,我们扩展别人的库的时候,如果使用对象作为键名,就不用担心自己的属性与原作者的属性同名。
如果 Map 的键是一个简单类型的值(数字、字符串、布尔值),则只要两个值严格相等,Map 将其视为一个键,比如 0 和 -0 就是一个键,布尔值 true 和字符串 true 则是两个不同的键。另外,undefined 和 null 也是两个不同的键。虽然 NaN 不严格相等于自身,但 Map 将其视为同一个键。
| |
Map 的属性及方法
属性:
constructor:构造函数
size:返回字典中所包含的元素个数
1 2 3 4 5 6const map = new Map([ ['name', 'An'], ['des', 'JS'] ]); map.size // 2
操作方法:
- set(key, value):向字典中添加新元素
- get(key):通过键查找特定的数值并返回
- has(key):判断字典中是否存在键 key
- delete(key):通过键 key 从字典中移除对应的数据
- clear():将这个字典中的所有元素删除
遍历方法
- Keys():将字典中包含的所有键名以迭代器形式返回
- values():将字典中包含的所有数值以迭代器形式返回
- entries():返回所有成员的迭代器
- forEach():遍历字典的所有成员
| |
Map 结构的默认遍历器接口(Symbol.iterator 属性),就是 entries 方法。
| |
Map 结构转为数组结构,比较快速的方法是使用扩展运算符(…)。
对于 forEach ,看一个例子
| |
在这个例子中, forEach 方法的回调函数的 this,就指向 reporter
与其他数据结构的相互转换
Map 转 Array
1 2const map = new Map([[1, 1], [2, 2], [3, 3]]) console.log([...map]) // [[1, 1], [2, 2], [3, 3]]Array 转 Map
1 2const map = new Map([[1, 1], [2, 2], [3, 3]]) console.log(map) // Map {1 => 1, 2 => 2, 3 => 3}Map 转 Object
因为 Object 的键名都为字符串,而 Map 的键名为对象,所以转换的时候会把非字符串键名转换为字符串键名。
1 2 3 4 5 6 7 8 9function mapToObj(map) { let obj = Object.create(null) for (let [key, value] of map) { obj[key] = value } return obj } const map = new Map().set('name', 'An').set('des', 'JS') mapToObj(map) // {name: "An", des: "JS"}Object 转 Map
1 2 3 4 5 6 7 8 9function objToMap(obj) { let map = new Map() for (let key of Object.keys(obj)) { map.set(key, obj[key]) } return map } objToMap({'name': 'An', 'des': 'JS'}) // Map {"name" => "An", "des" => "JS"}Map 转 JSON
1 2 3 4 5 6function mapToJson(map) { return JSON.stringify([...map]) } let map = new Map().set('name', 'An').set('des', 'JS') mapToJson(map) // [["name","An"],["des","JS"]]JSON 转 Map
1 2 3 4 5function jsonToStrMap(jsonStr) { return objToMap(JSON.parse(jsonStr)); } jsonToStrMap('{"name": "An", "des": "JS"}') // Map {"name" => "An", "des" => "JS"}
# 4. WeakMap
WeakMap 对象是一组键值对的集合,其中的键是弱引用对象,而值可以是任意。
注意,WeakMap 弱引用的只是键名,而不是键值。键值依然是正常引用。
WeakMap 中,每个键对自己所引用对象的引用都是弱引用,在没有其他引用和该键引用同一对象,这个对象将会被垃圾回收(相应的 key 则变成无效的),所以,WeakMap 的 key 是不可枚举的。
属性:
- constructor:构造函数
方法:
- has(key):判断是否有 key 关联对象
- get(key):返回 key 关联对象(没有则则返回 undefined)
- set(key):设置一组 key 关联对象
- delete(key):移除 key 的关联对象
| |
# 5. 总结
- Set
- 成员唯一、无序且不重复
- [value, value],键值与键名是一致的(或者说只有键值,没有键名)
- 可以遍历,方法有:add、delete、has
- WeakSet
- 成员都是对象
- 成员都是弱引用,可以被垃圾回收机制回收,可以用来保存 DOM 节点,不容易造成内存泄漏
- 不能遍历,方法有 add、delete、has
- Map
- 本质上是键值对的集合,类似集合
- 可以遍历,方法很多可以跟各种数据格式转换
- WeakMap
- 只接受对象作为键名(null 除外),不接受其他类型的值作为键名
- 键名是弱引用,键值可以是任意的,键名所指向的对象可以被垃圾回收,此时键名是无效的
- 不能遍历,方法有 get、set、has、delete
# 6. 扩展:Object 与 Set、Map
Object 与 Set
1 2 3 4 5 6 7 8 9 10 11 12// Object const properties1 = { 'width': 1, 'height': 1 } console.log(properties1['width']? true: false) // true // Set const properties2 = new Set() properties2.add('width') properties2.add('height') console.log(properties2.has('width')) // trueObject 与 Map
JS 中的对象(Object),本质上是键值对的集合(hash 结构)
| |
但当以一个 DOM 节点作为对象 data 的键,对象会被自动转化为字符串 [Object HTMLCollection],所以说,Object 结构提供了 字符串 - 值 对应,Map 则提供了 值 - 值 的对应
# 8. ES5/ES6 的继承除了写法以外还有什么区别?
这个问题比较复杂,暂时还不懂 url
ES5 和 ES6 子类 this 生成顺序不同。ES5 的继承先生成了子类实例,再调用父类的构造函数修饰子类实例,ES6 的继承先生成父类实例,再调用子类的构造函数修饰父类实例。这个差别使得 ES6 可以继承内置对象。
| |
# 9. 3 个判断数组的方法,请分别介绍它们之间的区别和优劣
| |
| |
instanceof 是判断类型的 prototype 是否出现在对象的原型链中,但是对象的原型可以随意修改,所以这种判断并不准确。
| |
# 10.介绍模块化发展历程
可从 IIFE、AMD、CMD、CommonJS、UMD、webpack(require.ensure)、ES Module、`` 这几个角度考虑。
https://www.processon.com/view/link/5c8409bbe4b02b2ce492286a#map
模块化主要是用来抽离公共代码,隔离作用域,避免变量冲突等。
IIFE: 使用自执行函数来编写模块化,特点:在一个单独的函数作用域中执行代码,避免变量冲突。
| |
AMD: 使用 requireJS 来编写模块化,特点:依赖必须提前声明好。
| |
CMD: 使用 seaJS 来编写模块化,特点:支持动态引入依赖文件。
| |
CommonJS: nodejs 中自带的模块化。
| |
UMD:兼容 AMD,CommonJS 模块化语法。
webpack(require.ensure):webpack 2.x 版本中的代码分割。
ES Modules: ES6 引入的模块化,支持 import 来引入另一个 js 。
| |
# 11.全局作用域中,用 Const 和 Let 声明的变量不在 Window 上,那到底在哪里?如何去获取?
主要还是得好好学学 js 作用域那一块,同时 es5、es6 区别语法等各种坑特别多得注意
在 ES5 中,顶层对象的属性和全局变量是等价的,var 命令和 function 命令声明的全局变量,自然也是顶层对象。
| |
但 ES6 规定,var 命令和 function 命令声明的全局变量,依旧是顶层对象的属性,但 let 命令、const 命令、class 命令声明的全局变量,不属于顶层对象的属性。
| |
在哪里?怎么获取?通过在设置断点,看看浏览器是怎么处理的:
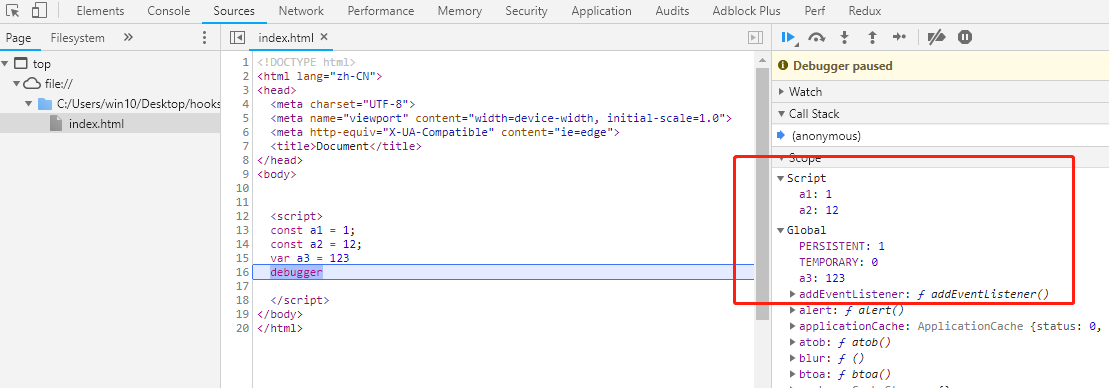
通过上图也可以看到,在全局作用域中,用 let 和 const 声明的全局变量并没有在全局对象中,只是一个块级作用域(Script)中
怎么获取?在定义变量的块级作用域中就能获取啊,既然不属于顶层对象,那就不加 window(global)呗。
| |
# 12.使用 sort() 对数组 [3, 15, 8, 29, 102, 22] 进行排序,输出结果
sort 函数,可以接收一个函数,返回值是比较两个数的相对顺序的值
- 默认没有函数 是按照
UTF-16排序的,对于字母数字 你可以利用ASCII进行记忆
| |
- 带函数的比较
| |
- 返回值大于 0 即 a-b > 0 , a 和 b 交换位置
- 返回值大于 0 即 a-b < 0 , a 和 b 位置不变
- 返回值等于 0 即 a-b = 0 , a 和 b 位置不变
对于函数体返回
b-a可以类比上面的返回值进行交换位置
# 13. JS **JavaScript Demo: Function.call() **JavaScript Demo: Function.apply()
call() 方法接受的是一个参数列表,而 apply() 方法接受的是一个包含多个参数的数组。
# 14.输出以下代码的执行结果并解释为什么
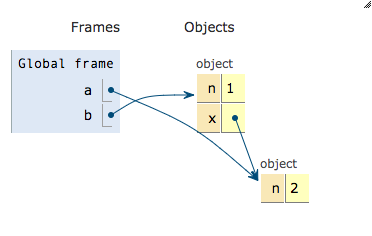
| |
结果: undefined {n:2}
首先,a 和 b 同时引用了{n:2}对象,接着执行到 a.x = a = {n:2}语句,尽管赋值是从右到左的没错,但是.的优先级比=要高,所以这里首先执行 a.x,相当于为 a(或者 b)所指向的{n:1}对象新增了一个属性 x,即此时对象将变为{n:1;x:undefined}。之后按正常情况,从右到左进行赋值,此时执行 a ={n:2}的时候,a 的引用改变,指向了新对象{n:2},而 b 依然指向的是旧对象。之后执行 a.x = {n:2}的时候,并不会重新解析一遍 a,而是沿用最初解析 a.x 时候的 a,也即旧对象,故此时旧对象的 x 的值为{n:2},旧对象为 {n:1;x:{n:2}},它被 b 引用着。 后面输出 a.x 的时候,又要解析 a 了,此时的 a 是指向新对象的 a,而这个新对象是没有 x 属性的,故访问时输出 undefined;而访问 b.x 的时候,将输出旧对象的 x 的值,即{n:2}。
# 15. 数组里 10 万个数据,取第一个元素和第 99999 个元素时间相差多少
js 中数组元素的存储方式并不是连续的,而是哈希映射关系。哈希映射关系,可以通过键名 key,直接计算出值存储的位置,所以查找起来很快。推荐一下这篇文章: 深究 JavaScript 数组
# 16.输出以下代码运行结果
| |
这题考察的是对象的键名的转换。
- 对象的键名只能是字符串和 Symbol 类型。
- 其他类型的键名会被转换成字符串类型。
- 对象转字符串默认会调用 toString 方法。
| |
前面说的很清楚了,除了 Symbol,如果想要不被覆盖 可以使用 ES6 提供的 Map
| |
# 17.var、let 和 Const 区别的实现原理是什么
- var:遇到有 var 的作用域,在任何语句执行前都已经完成了声明和初始化,也就是变量提升而且拿到 undefined 的原因由来
- function: 声明、初始化、赋值一开始就全部完成,所以函数的变量提升优先级更高
- let:解析器进入一个块级作用域,发现 let 关键字,变量只是先完成声明,并没有到初始化那一步。此时如果在此作用域提前访问,则报错 xx is not defined,这就是暂时性死区的由来。等到解析到有 let 那一行的时候,才会进入初始化阶段。如果 let 的那一行是赋值操作,则初始化和赋值同时进行
- const、class 都是同 let 一样的道理
比如解析如下代码步骤:
| |
步骤:
- 发现作用域有 let a,先注册个 a,仅仅注册
- 没用的第一行
- 没用的第二行
- a is not defined,暂时性死区的表现
- 假设前面那行不报错,a 初始化为 undefined
- a 赋值为 1
对比于 var,let、const 只是解耦了声明和初始化的过程,var 是在任何语句执行前都已经完成了声明和初始化,let、const 仅仅是在任何语句执行前只完成了声明
# 18.Async/Await 如何通过同步的方式实现异步
看了第一个回答,讲的挺深入底层的,但我现在还不太看得懂,先占个坑。
# 19.输出运行结果
| |
结果:
| |
同理
| |
先看此题的上半部分做了什么,首先定义了一个叫 Foo 的函数,之后为 Foo 创建了一个叫 getName 的静态属性存储了一个匿名函数,之后为 Foo 的原型对象新创建了一个叫 getName 的匿名函数。之后又通过函数变量表达式创建了一个 getName 的函数,最后再声明一个叫 getName 函数。
第一问的 Foo.getName 自然是访问 Foo 函数上存储的静态属性,答案自然是 2,这里就不需要解释太多的,一般来说第一问对于稍微懂 JS 基础的同学来说应该是没问题的,当然我们可以用下面的代码来回顾一下基础,先加深一下了解
Foo.getName();
自然是访问 Foo 函数上存储的静态属性,答案自然是 2,这里就不需要解释太多的,一般来说第一问对于稍微懂 JS 基础的同学来说应该是没问题的,当然我们可以用下面的代码来回顾一下基础,先加深一下了解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15function User(name) { var name = name; //私有属性 this.name = name; //公有属性 function getName() { //私有方法 return name; } } User.prototype.getName = function() { //公有方法 return this.name; } User.name = 'Wscats'; //静态属性 User.getName = function() { //静态方法 return this.name; } var Wscat = new User('Wscats'); //实例化注意下面这几点:
- 调用公有方法,公有属性,我们必需先实例化对象,也就是用 new 操作符实化对象,就可构造函数实例化对象的方法和属性,并且公有方法是不能调用私有方法和静态方法的
- 静态方法和静态属性就是我们无需实例化就可以调用
- 而对象的私有方法和属性,外部是不可以访问的
getName();
既然是直接调用那么就是访问当前上文作用域内的叫 getName 的函数,所以这里应该直接把关注点放在 4 和 5 上,跟 1 2 3 都没什么关系。当然后来我问了我的几个同事他们大多数回答了 5。此处其实有两个坑,一是变量声明提升,二是函数表达式和函数声明的区别。
我们来看看为什么,可参考 (1) 关于 Javascript 的函数声明和函数表达式 (2) 关于 JavaScript 的变量提升
在 Javascript 中,定义函数有两种类型
函数声明
1 2 3 4// 函数声明 function wscat(type) { return type === "wscat"; }函数表达式
1 2 3 4// 函数表达式 var oaoafly = function(type) { return type === "oaoafly"; }先看下面这个经典问题,在一个程序里面同时用函数声明和函数表达式定义一个名为 getName 的函数
1 2 3 4 5 6 7 8 9getName() //oaoafly var getName = function() { console.log('wscat') } getName() //wscat function getName() { console.log('oaoafly') } getName() //wscat上面的代码看起来很类似,感觉也没什么太大差别。但实际上,Javascript 函数上的一个“陷阱”就体现在 Javascript 两种类型的函数定义上。
- JavaScript 解释器中存在一种变量声明被提升的机制,也就是说函数声明会被提升到作用域的最前面,即使写代码的时候是写在最后面,也还是会被提升至最前面。
- 而用函数表达式创建的函数是在运行时进行赋值,且要等到表达式赋值完成后才能调用
1 2 3 4 5 6 7 8 9 10 11var getName //变量被提升,此时为undefined getName() //oaoafly 函数被提升 这里受函数声明的影响,虽然函数声明在最后可以被提升到最前面了 var getName = function() { console.log('wscat') } //函数表达式此时才开始覆盖函数声明的定义 getName() //wscat function getName() { console.log('oaoafly') } getName() //wscat 这里就执行了函数表达式的值所以可以分解为这两个简单的问题来看清楚区别的本质
1 2 3 4 5 6 7 8 9 10 11 12var getName; console.log(getName) //undefined getName() //Uncaught TypeError: getName is not a function var getName = function() { console.log('wscat') } var getName; console.log(getName) //function getName() {console.log('oaoafly')} getName() //oaoafly function getName() { console.log('oaoafly') }这个区别看似微不足道,但在某些情况下确实是一个难以察觉并且“致命“的陷阱。出现这个陷阱的本质原因体现在这两种类型在函数提升和运行时机(解析时/运行时)上的差异。
当然我们给一个总结:Javascript 中函数声明和函数表达式是存在区别的,函数声明在 JS 解析时进行函数提升,因此在同一个作用域内,不管函数声明在哪里定义,该函数都可以进行调用。而函数表达式的值是在 JS 运行时确定,并且在表达式赋值完成后,该函数才能调用。
所以第二问的答案就是 4,5 的函数声明被 4 的函数表达式覆盖了
Foo().getName();
先执行了 Foo 函数,然后调用 Foo 函数的返回值对象的 getName 属性函数。
Foo 函数的第一句
getName = function () { alert (1); };是一句函数赋值语句,注意它没有 var 声明,所以先向当前 Foo 函数作用域内寻找 getName 变量,没有。再向当前函数作用域上层,即外层作用域内寻找是否含有 getName 变量,找到了,也就是第二问中的 alert(4) 函数,将此变量的值赋值为function(){alert(1)}。此处实际上是将外层作用域内的 getName 函数修改了。
注意:此处若依然没有找到会一直向上查找到 window 对象,若 window 对象中也没有 getName 属性,就在 window 对象中创建一个 getName 变量。
之后 Foo 函数的返回值是 this,而 JS 的 this 问题已经有非常多的文章介绍,这里不再多说。
简单的讲,this 的指向是由所在函数的调用方式决定的。而此处的直接调用方式,this 指向 window 对象。
遂 Foo 函数返回的是 window 对象,相当于执行
window.getName(),而 window 中的 getName 已经被修改为 alert(1),所以最终会输出 1
此处考察了两个知识点,一个是变量作用域问题,一个是 this 指向问题
我们可以利用下面代码来回顾下这两个知识点:1 2 3 4 5 6 7 8 9 10 11 12 13var name = "Wscats"; //全局变量 window.name = "Wscats"; //全局变量 function getName() { name = "Oaoafly"; //去掉var变成了全局变量 var privateName = "Stacsw"; return function() { console.log(this); //window return privateName } } var getPrivate = getName("Hello"); //当然传参是局部变量,但函数里面我没有接受这个参数 console.log(name) //Oaoafly console.log(getPrivate()) //Stacsw因为 JS 没有块级作用域,但是函数是能产生一个作用域的,函数内部不同定义值的方法会直接或者间接影响到全局或者局部变量,函数内部的私有变量可以用闭包获取,函数还真的是第一公民呀~
而关于 this,this 的指向在函数定义的时候是确定不了的,只有函数执行的时候才能确定 this 到底指向谁,实际上 this 的最终指向的是那个调用它的对象
所以第三问中实际上就是 window 在调用**Foo()**函数,所以 this 的指向是 window
1 2window.Foo().getName(); //->window.getName();getName();
直接调用 getName 函数,相当于
window.getName(),因为这个变量已经被 Foo 函数执行时修改了,遂结果与第三问相同,为 1,也就是说 Foo 执行后把全局的 getName 函数给重写了一次,所以结果就是 Foo() 执行重写的那个 getName 函数new Foo.getName()
下面是 JS 运算符的优先级表格,从高到低排列。可参考 MDN 运算符优先级
优先级 运算类型 关联性 运算符 19 圆括号 n/a ( … ) 18 成员访问 从左到右 … . … 需计算的成员访问 从左到右 … [ … ] new (带参数列表) n/a new … ( … ) 17 函数调用 从左到右 … ( … ) new (无参数列表) 从右到左 new … 16 后置递增 (运算符在后) n/a … ++ 后置递减 (运算符在后) n/a … – 15 逻辑非 从右到左 ! … 按位非 从右到左 ~ … 一元加法 从右到左 + … 一元减法 从右到左 - … 前置递增 从右到左 ++ … 前置递减 从右到左 – … typeof 从右到左 typeof … void 从右到左 void … delete 从右到左 delete … 14 乘法 从左到右 … * … 除法 从左到右 … / … 取模 从左到右 … % … 13 加法 从左到右 … + … 减法 从左到右 … - … 12 按位左移 从左到右 … « … 按位右移 从左到右 … » … 无符号右移 从左到右 … »> … 11 小于 从左到右 … < … 小于等于 从左到右 … <= … 大于 从左到右 … > … 大于等于 从左到右 … >= … in 从左到右 … in … instanceof 从左到右 … instanceof … 10 等号 从左到右 … == … 非等号 从左到右 … != … 全等号 从左到右 … === … 非全等号 从左到右 … !== … 9 按位与 从左到右 … & … 8 按位异或 从左到右 … ^ … 7 按位或 从左到右 … 按位或 … 6 逻辑与 从左到右 … && … 5 逻辑或 从左到右 … 逻辑或 … 4 条件运算符 从右到左 … ? … : … 3 赋值 从右到左 … = … … += … … -= … … *= … … /= … … %= … … «= … … »= … … »>= … … &= … … ^= … … 或= … 2 yield 从右到左 yield … yield* 从右到左 yield* … 1 展开运算符 n/a … … 0 逗号 从左到右 … , …
这题首先看优先级的第 18 和第 17 都出现关于 new 的优先级,new (带参数列表) 比 new (无参数列表) 高比函数调用高,跟成员访问同级
new Foo.getName(); 的优先级是这样的
相当于是:
| |
- 点的优先级 (18) 比 new 无参数列表 (17) 优先级高
- 当点运算完后又因为有个括号
(),此时就是变成 new 有参数列表 (18),所以直接执行 new,当然也可能有朋友会有疑问为什么遇到 () 不函数调用再 new 呢,那是因为函数调用 (17) 比 new 有参数列表 (18) 优先级低
.成员访问 (18)-> new 有参数列表 (18)
所以这里实际上将 getName 函数作为了构造函数来执行,遂弹出 2。
这一题比上一题的唯一区别就是在 Foo 那里多出了一个括号,这个有括号跟没括号我们在第五问的时候也看出来优先级是有区别的
1(new Foo()).getName()那这里又是怎么判断的呢?首先 new 有参数列表 (18) 跟点的优先级 (18) 是同级,同级的话按照从左向右的执行顺序,所以先执行 new 有参数列表 (18) 再执行点的优先级 (18),最后再函数调用 (17)
new 有参数列表 (18)-> .成员访问 (18)-> () 函数调用 (17)
这里还有一个小知识点,Foo 作为构造函数有返回值,所以这里需要说明下 JS 中的构造函数返回值问题。
# 构造函数的返回值
在传统语言中,构造函数不应该有返回值,实际执行的返回值就是此构造函数的实例化对象。
而在 JS 中构造函数可以有返回值也可以没有。
- 没有返回值则按照其他语言一样返回实例化对象。
| |
- 若有返回值则检查其返回值是否为引用类型。如果是非引用类型,如基本类型(String,Number,Boolean,Null,Undefined)则与无返回值相同,实际返回其实例化对象。
| |
- 若返回值是引用类型,则实际返回值为这个引用类型。
| |
原题中,由于返回的是 this,而 this 在构造函数中本来就代表当前实例化对象,最终 Foo 函数返回实例化对象。
之后调用实例化对象的 getName 函数,因为在 Foo 构造函数中没有为实例化对象添加任何属性,当前对象的原型对象 (prototype) 中寻找 getName 函数。
当然这里再拓展个题外话,如果构造函数和原型链都有相同的方法,如下面的代码,那么默认会拿构造函数的公有方法而不是原型链,这个知识点在原题中没有表现出来,后面改进版我已经加上。
| |
new new Foo().getName();同样是运算符优先级问题。做到这一题其实我已经觉得答案没那么重要了,关键只是考察面试者是否真的知道面试官在考察我们什么。
最终实际执行为:1new ((new Foo()).getName)();new 有参数列表 (18)-> new 有参数列表 (18)
先初始化 Foo 的实例化对象,然后将其原型上的 getName 函数作为构造函数再次 new,所以最终结果为 3
进阶版
| |
# 20.写出结果
| |
True false
new String() 返回的是对象
的时候,实际运行的是 String(‘11’) new String(‘11’).toString();
=== 不再赘述。
| |
# 21.写出结果
| |
- 1 + “1”
加性操作符:如果只有一个操作数是字符串,则将另一个操作数转换为字符串,然后再将两个字符串拼接起来
所以值为:“11”
- 2 * “2”
乘性操作符:如果有一个操作数不是数值,则在后台调用 Number() 将其转换为数值
- [1, 2] + [2, 1]
Javascript 中所有对象基本都是先调用 valueOf 方法,如果不是数值,再调用 toString 方法。
所以两个数组对象的 toString 方法相加,值为:“1,22,1”
- “a” + + “b”
后边的“+”将作为一元操作符,如果操作数是字符串,将调用 Number 方法将该操作数转为数值,如果操作数无法转为数值,则为 NaN。
所以值为:“aNaN”
以上均参考:《Javascript 高级程序设计》
稍稍补充一小下: 加号作为一元运算符时,其后面的表达式将进行 ToNumber(参考es规范) 的抽象操作:
- true -> 1
- false -> 0
- undefined -> NaN
- null -> 0
- ’字符串‘ -> 字符串为纯数字时返回转换后的数字(十六进制返回十进制数),否则返回 NaN
- 对象 -> 通过 ToPrimitive 拿到基本类型值,然后再进行 ToNumber 操作
| |
# 22.为什么 For 循环嵌套顺序会影响性能?
| |
想起来之前在书上看到的,let 每个循环都会初始化,所以外层循环次数越大,内层变量初始化次数越多,影响性能。
# 23.输出以下代码执行结果
| |
# 24.理解任务队列 (消息队列)
一种是同步任务(synchronous),另一种是异步任务(asynchronous)
| |
如果你的回答是 A,恭喜你答对了,因为这是同步任务,程序由上到下执行,遇到 while() 死循环,下面语句就没办法执行。
| |
如果你的答案是 A,恭喜你现在对 js 运行机制已经有个粗浅的认识了! 题目中的 setTimeout() 就是个异步任务。在所有同步任务执行完之前,任何的异步任务是不会执行的
| |
new Promise(xx) 相当于同步任务, 会立即执行
所以: x,y,z 三个任务是几乎同时开始的, 最后的时间依然是 10*1000ms (比这稍微大一点点, 超出部分在 1x1000ms 之内)
但如果稍稍修改
| |
# 25.for In 和 for of 的区别
for..of 适用遍历数/数组对象/字符串/map/set 等拥有迭代器对象的集合.但是不能遍历对象,因为没有迭代器对象.与 forEach() 不同的是,它可以正确响应 break、continue 和 return 语句
for-of 循环不支持普通对象,但如果你想迭代一个对象的属性,你可以用 for-in 循环(这也是它的本职工作)或内建的 Object.keys() 方法:
# 26.数组扁平化处理:实现一个 Flatten 方法,使得输入一个数组,该数组里面的元素也可以是数组,该方法会输出一个扁平化的数组
| |
年轻的我是用递归实现的 QAQ,我的答案
| |
其实你还可以这样
| |
还可以使用 ES6 拓展运算符
| |
这是李魁昊写的:
| |
# 26.Async/await 和 Promise
Async/await 是 generator 和 Promise 的语法糖,但仅仅是语法糖吗? 它们两个的性能有没有区别呢, 又或者 promise.then() 和 await 同为微任务,但是它们的执行顺序是怎样的呢?
Async/Await 与 Promise 最大区别在于:await b() 会暂停所在的 async 函数的执行;而 Promise.then(b) 将 b 函数加入回调链中之后,会继续执行当前函数。对于堆栈来说,这个不同点非常关键。
当一个 Promise 链抛出一个未处理的错误时,无论我们使用 await b() 还是 Promise.then(b),JavaScript 引擎都需要打印错误信息及其堆栈。对于 JavaScript 引擎来说,两者获取堆栈的方式是不同的。
# Promise.then()
观察下面代码, 假设 b() 返回一个 promise
| |
当调用 a() 函数时,这些事情同步发生,b() 函数产生一个 promise 对象,调用 then 方法,Promise 会在将来的某个时刻 resolve,也就是把 then 里的回调函数添加到回调链。(如果这一块不太明白,可以仔细学习 promise,或者读一读 promise 源码并尝试写一写,相信你更通透),这样,a() 函数就执行完了,在这个过程中,a() 函数并不会暂停,因此在异步函数 resolve 的时候,a() 的作用域已经不存在了,那要如何生成包含 a() 的堆栈信息呢? 为了解决这个问题,JavaScripts 引擎要做一些额外的工作;它会及时记录并保存堆栈信息。对于 V8 引擎来说,这些堆栈信息随着 Promise 在 Promise 链中传递,这样 c() 函数在需要的时候也能获取堆栈信息。但是这无疑造成了额外的开销,会降低性能;保存堆栈信息会占用额外的内存。
# Await
我们可以用 Async/await 来实现一下
| |
使用 await 的时候,无需存储堆栈信息,因为存储 b() 到 a() 的指针的足够了。当 b() 函数执行的时候,a() 函数被暂停了,因此 a() 函数的作用域还在内存可以访问。如果 b() 抛出一个错误,堆栈通过指针迅速生成。如果 c() 函数抛出一个错误,堆栈信息也可以像同步函数一样生成,因为 c() 是在 a() 中执行的。不论是 b() 还是 c(),我们都不需要去存储堆栈信息,因为堆栈信息可以在需要的时候立即生成。而存储指针,显然比存储堆栈更加节省内存
# 结论
很多 ECMAScript 语法特性看起来都只是些语法糖,其实并非如此,至少 Async/await 绝不仅仅是语法糖 为了让 JavaScript 引擎处理堆栈的方式性能更高,请尽量使用 Async/await,而不是直接使用 Promise。
# 27.CommonJS 和 ES6 模块化的区别以及如何解决让 CommonJS 导出的模块也能改变其内部变量
# ES6 模块化
1.export
export 可以输出变量、函数和类,切记不可直接输出值,否则会报错
2.export default
一个模块只能有一个默认输出,因此 export default 命令只能使用一次。所以,import 命令后面才不用加大括号,因为只可能唯一对应 export default 命令
3.import
import 命令接受一对大括号,里面指定要从其他模块导入的变量名。大括号里面的变量名,必须与被导入模块对外接口的名称相同。如果想为输入的变量重新取一个名字,import 命令要使用 as 关键字,将输入的变量重命名。
import {sum} from 'index.js'; import {sum,age,name} from 'index.js'; import {sum as hg, age as nl, name as xm} from 'index.js';
import 只会导入一次,无论你引入多少次
有提升效果,import 会自动提升到顶部,首先执行
import 命令输入的变量都是只读的,因为它的本质是输入接口。也就是说,不允许在加载模块的脚本里面,改写接口。如果脚本加载了变量,对其重新赋值就会报错,因为变量是一个只读的接口。但是,如果是一个对象,改写对象的属性是允许的。(对象只能改变值但不能改变引用)
由于 import 是静态执行,所以不能使用表达式和变量,这些只有在运行时才能得到结果的语法结构。
import 后面的 from 指定模块文件的位置,可以是相对路径,也可以是绝对路径,.js 后缀可以省略。如果只是模块名,不带有路径,那么必须有配置文件,告诉
JavaScript 引擎该模块的位置。
循环加载时,ES6 模块是动态引用。只要两个模块之间存在某个引用,代码就能够执行。
# CommonJs
1.module.exports
2.require
CommonJs 模块的特点
所有代码都运行在模块作用域,不会污染全局作用域。
模块可以多次加载,但是只会在第一次加载时运行一次,然后运行结果就被缓存了,以后再加载,就直接读取缓存结果。要想让模块再次运行,必须清除缓存。
模块加载的顺序,按照其在代码中出现的顺序。
CommonJs 规范加载模块是同步的,即只有加载完成,才能执行后面的操作
CommonJs 模块的加载机制是,输入的是被输出的值的拷贝,即,一旦输出一个值,模块内部的变化影响不到这个值 (关于这一条详细看下方举例 1⃣️)
对于基本数据类型,属于复制。即会被模块缓存。同时,在另一个模块可以对该模块输出的变量重新赋值。对于复杂数据类型,属于浅拷贝。由于两个模块引用的对象指向同一个内存空间,因此对该模块的值做修改时会影响另一个模块。
当使用 require 命令加载某个模块时,就会运行整个模块的代码。
循环加载时,属于加载时执行。即脚本代码在 require 的时候,就会全部执行。一旦出现某个模块被 " 循环加载 “,就只输出已经执行的部分,还未执行的部分不会输出。
| |
经过事实的检验我们可以得出,在 CommonJs 中,输入的是被输出的值的拷贝。
上面代码说明,lib.js 模块加载以后,它的内部变化就影响不到输出的 mod.counter 了。这是因为 mod.counter 是一个原始类型的值,会被缓存。除非写成一个函数,才能得到内部变动后的值。
那 commonJs 怎么办呢 当然有!
| |
再看 ES6 模块化
| |
从上面我们看出,CommonJS 模块输出的是值的拷贝,也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。而 ES6 模块是动态地去被加载的模块取值,并且变量总是绑定其所在的模块。
另外 CommonJS 加载的是一个对象(即 module.exports 属性),该对象只有在脚本运行完才会生成。而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
28. webpack 中 loader 和 plugin 的区别是什么
# 主要区别
loader 用于加载某些资源文件。 因为 webpack 本身只能打包 commonjs 规范的 js 文件,对于其他资源例如 css,图片,或者其他的语法集,比如 jsx, coffee,是没有办法加载的。 这就需要对应的 loader 将资源转化,加载进来。从字面意思也能看出,loader 是用于加载的,它作用于一个个文件上。
plugin 用于扩展 webpack 的功能。它直接作用于 webpack,扩展了它的功能。当然 loader 也时变相的扩展了 webpack ,但是它只专注于转化文件(transform)这一个领域。而 plugin 的功能更加的丰富,而不仅局限于资源的加载。
# 29.手写 call、apply、bind 实现及详解
apply 接收两个参数,第一个参数为函数上下文 this,第二个参数为函数参数只不过是通过一个数组的形式传入的。
| |
call 接收多个参数,第一个为函数上下文也就是 this,后边参数为函数本身的参数。
| |

bind 接收多个参数,第一个是 bind 返回值返回值是一个函数上下文的 this,不会立即执行。
| |
接下来搓搓手实现 call、apply 和 bind
# Call
# 定义与使用
Function.prototype.call(): developer.mozilla.org/zh-CN/docs/…
| |
# 手写实现
| |
# Apply
# 定义与使用
Function.prototype.apply(): developer.mozilla.org/zh-CN/docs/…
| |
# 手写实现
| |
# Bind
# 定义与使用
Function.prototype.bind() : developer.mozilla.org/zh-CN/docs/…
| |
# 手写实现
| |