GYM
# Env
首先我们可以通过如下代码调用并展示(可视化)一个环境:
| |
该代码创建了一个著名的 CartPole 环境,用于控制小车使上面的杆保持竖直不倒,如下图所示。在每一次迭代中,我们从动作空间中采样了一个随机动作(本环境中只有**「向左」和「向右」**两个动作)并执行。

# Pendulum
https://blog.csdn.net/u013745804/article/details/78397106
gym学习及二次开发 https://zhuanlan.zhihu.com/p/26985029
# Observation
为了做出更加合适的动作,我们需要先了解环境的反馈。环境的 step 函数可以返回我们想要的值,其总共返回如下四个值:
observation(「object」):一个环境特定的对象以表示当前环境的观测状态,如相机的像素数据,机器人的关节角度和速度,桌游中的即时战况等reward(「float」):前一个动作所获得的奖励值,其范围往往随着环境的变化而各不相同,但目标一般都是提升总奖励值done(「boolean」):是否需要重置(reset)环境,不同的环境会有不同的终止条件,包括执行动作的次数限制、状态的变化阈值等info(「dict」):输出学习过程中的相关信息,一般用于调试
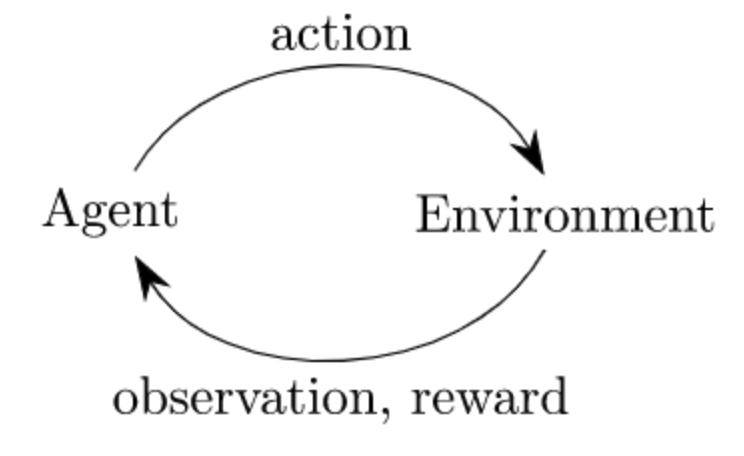
通过上述函数,我们可以实现经典的**「代理-环境循环」**,在每个时间步,代理选择一个动作,环境返回一个观察(状态)和一个奖励:
# Space
在 Gym 中,状态和动作都是通过 Space 类型来表示的,其可以定义连续或离散的子空间。最常用的两种 Space 是 Box 和 Discrete,在 CartPole 环境中状态空间和动作空间就分别对应这两种 Space:
| |
Discrete定义了一个从 0 开始取值的离散空间,而Box则可以表示一个m*n维的连续空间,需要为每个维度设置上下界。我们可以通过如下方式新建空间:
1 2 3 4 5 6 7 8 9 10from gym import spaces space = spaces.Discrete(8) # 包含 {0, 1, 2, ..., 7} 八个元素的集合 # 每一维相同的上下界 space_box_1 = Box(low=-1.0, high=2.0, shape=(3, 4), dtype=np.float32) # Box(3, 4) # 每一维不同的上下界 space_box_2 = Box(low=np.array([-1.0, -2.0]), high=np.array([2.0, 4.0]), dtype=np.float32) # Box(2,)