1. Scikit-learn与特征工程
Last updated
Sep 6, 2022
# 1. Scikit-learn 与特征工程
数据决定了机器学习的上限,而算法只是尽可能逼近这个上限”,这句话很好的阐述了数据在机器学习中的重要性。大部分直接拿过来的数据都是特征不明显的、没有经过处理的或者说是存在很多无用的数据,那么需要进行一些特征处理,特征的缩放等等,满足训练数据的要求。
我们将初次接触到 Scikit-learn 这个机器学习库的使用

Scikit-learn
- Python 语言的机器学习工具
- 所有人都适用,可在不同的上下文中重用
- 基于 NumPy、SciPy 和 matplotlib 构建
- 开源、商业可用 - BSD 许可
- 目前稳定版本 0.18
自 2007 年发布以来,scikit-learn 已经成为最给力的 Python 机器学习库(library)了。scikit-learn 支持的机器学习算法包括分类,回归,降维和聚类。还有一些特征提取(extracting features)、数据处理(processing data)和模型评估(evaluating models)的模块。作为 Scipy 库的扩展,scikit-learn 也是建立在 Python 的 NumPy 和 matplotlib 库基础之上。NumPy 可以让 Python 支持大量多维矩阵数据的高效操作,matplotlib 提供了可视化工具,SciPy 带有许多科学计算的模型。
scikit-learn 文档完善,容易上手,丰富的 API,使其在学术界颇受欢迎。开发者用 scikit-learn 实验不同的算法,只要几行代码就可以搞定。scikit-learn 包括许多知名的机器学习算法的实现,包括 LIBSVM 和 LIBLINEAR。还封装了其他的 Python 库,如自然语言处理的 NLTK 库。另外,scikit-learn 内置了大量数据集,允许开发者集中于算法设计,节省获取和整理数据集的时间。
安装的话参考下面步骤: 创建一个基于 Python3 的虚拟环境:
1
| mkvirtualenv -p /usr/local/bin/python3.6 ml3
|
在 ubuntu 的虚拟环境当中运行以下命令
1
| pip3 install Scikit-learn
|
然后通过导入命令查看是否可以使用:
# 数据的特征工程
从数据中抽取出来的对预测结果有用的信息,通过专业的技巧进行数据处理,是的特征能在机器学习算法中发挥更好的作用。优质的特征往往描述了数据的固有结构。 最初的原始特征数据集可能太大,或者信息冗余,因此在机器学习的应用中,一个初始步骤就是选择特征的子集,或构建一套新的特征集,减少功能来促进算法的学习,提高泛化能力和可解释性。
例如:你要查看不同地域女性的穿衣品牌情况,预测不同地域的穿衣品牌。如果其中含有一些男性的数据,是不是要将这些数据给去除掉
# 特征工程的意义
- 更好的特征意味着更强的鲁棒性
- 更好的特征意味着只需用简单模型
- 更好的特征意味着更好的结果
# 特征工程之特征处理
特征工程中最重要的一个环节就是特征处理,特征处理包含了很多具体的专业技巧
# 特征工程之特征抽取与特征选择
如果说特征处理其实就是在对已有的数据进行运算达到我们目标的数据标准。特征抽取则是将任意数据格式(例如文本和图像)转换为机器学习的数字特征。而特征选择是在已有的特征中选择更好的特征。后面会详细介绍特征选择主要区别于降维。
# 1.1 数据的来源与类型
大部分的数据都来自已有的数据库,如果没有的话也可以交给很多爬虫工程师去采集,来提供。也可以来自平时的记录,反正数据无处不在,大都是可用的。
# 数据的类型
按照机器学习的数据分类我们可以将数据分成:
- 标称型:标称型目标变量的结果只在有限目标集中取值,如真与假 (标称型目标变量主要用于分类)
- 数值型:数值型目标变量则可以从无限的数值集合中取值,如 0.100,42.001 等 (数值型目标变量主要用于回归分析)
按照数据的本身分布特性
那么什么是离散型和连续型数据呢?首先连续型数据是有规律的,离散型数据是没有规律的
- 离散变量是指其数值只能用自然数或整数单位计算的则为离散变量.例如,班级人数、进球个数、是否是某个类别等等
- 连续型数据是指在指定区间内可以是任意一个数值,例如,票房数据、花瓣大小分布数据
# 1.2 数据的特征抽取
现实世界中多数特征都不是连续变量,比如分类、文字、图像等,为了对非连续变量做特征表述,需要对这些特征做数学化表述,因此就用到了特征提取. sklearn.feature_extraction 提供了特征提取的很多方法
# 分类特征变量提取
我们将城市和环境作为字典数据,来进行特征的提取。
sklearn.feature_extraction.DictVectorizer(sparse = True)
将映射列表转换为 Numpy 数组或 scipy.sparse 矩阵
- sparse 是否转换为 scipy.sparse 矩阵表示,默认开启

方法
fit_transform(X,y)
应用并转化映射列表 X,y 为目标类型
inverse_transform(X[, dict_type])
将 Numpy 数组或 scipy.sparse 矩阵转换为映射列表
1
2
3
4
5
6
7
8
| from sklearn.feature_extraction import DictVectorizer
onehot = DictVectorizer() # 如果结果不用toarray,请开启sparse=False
instances = [{'city': '北京', 'temperature': 100}, {'city': '上海', 'temperature': 60},
{'city': '深圳', 'temperature': 30}]
X = onehot.fit_transform(instances).toarray()
print(onehot.inverse_transform(X))
print(onehot.get_feature_names())
print(X)
|
# 文本特征提取(只限于英文)
文本的特征提取应用于很多方面,比如说文档分类、垃圾邮件分类和新闻分类。那么文本分类是通过词是否存在、以及词的概率(重要性)来表示。
(1) 文档的中词的出现
数值为 1 表示词表中的这个词出现,为 0 表示未出现
sklearn.feature_extraction.text.CountVectorizer()
将文本文档的集合转换为计数矩阵(scipy.sparse matrices)
方法
fit_transform(raw_documents,y)
学习词汇词典并返回词汇文档矩阵
1
2
3
4
| from sklearn.feature_extraction.text import CountVectorizer
content = ["life is short,i like python","life is too long,i dislike python"]
vectorizer = CountVectorizer()
print(vectorizer.fit_transform(content).toarray())
|

需要 toarray() 方法转变为 numpy 的数组形式
温馨提示:每个文档中的词,只是整个语料库中所有词,的很小的一部分,这样造成特征向量的稀疏性(很多值为 0)为了解决存储和运算速度的问题,使用 Python 的 scipy.sparse 矩阵结构
(2)TF-IDF 表示词的重要性
TfidfVectorizer 会根据指定的公式将文档中的词转换为概率表示。(朴素贝叶斯介绍详细的用法)
class sklearn.feature_extraction.text.TfidfVectorizer()
方法
fit_transform(raw_documents,y)
学习词汇和 idf,返回术语文档矩阵。
1
2
3
4
5
| from sklearn.feature_extraction.text import TfidfVectorizer
content = ["life is short,i like python","life is too long,i dislike python"]
vectorizer = TfidfVectorizer(stop_words='english')
print(vectorizer.fit_transform(content).toarray())
print(vectorizer.vocabulary_)
|
# 文本特征提取(中文)

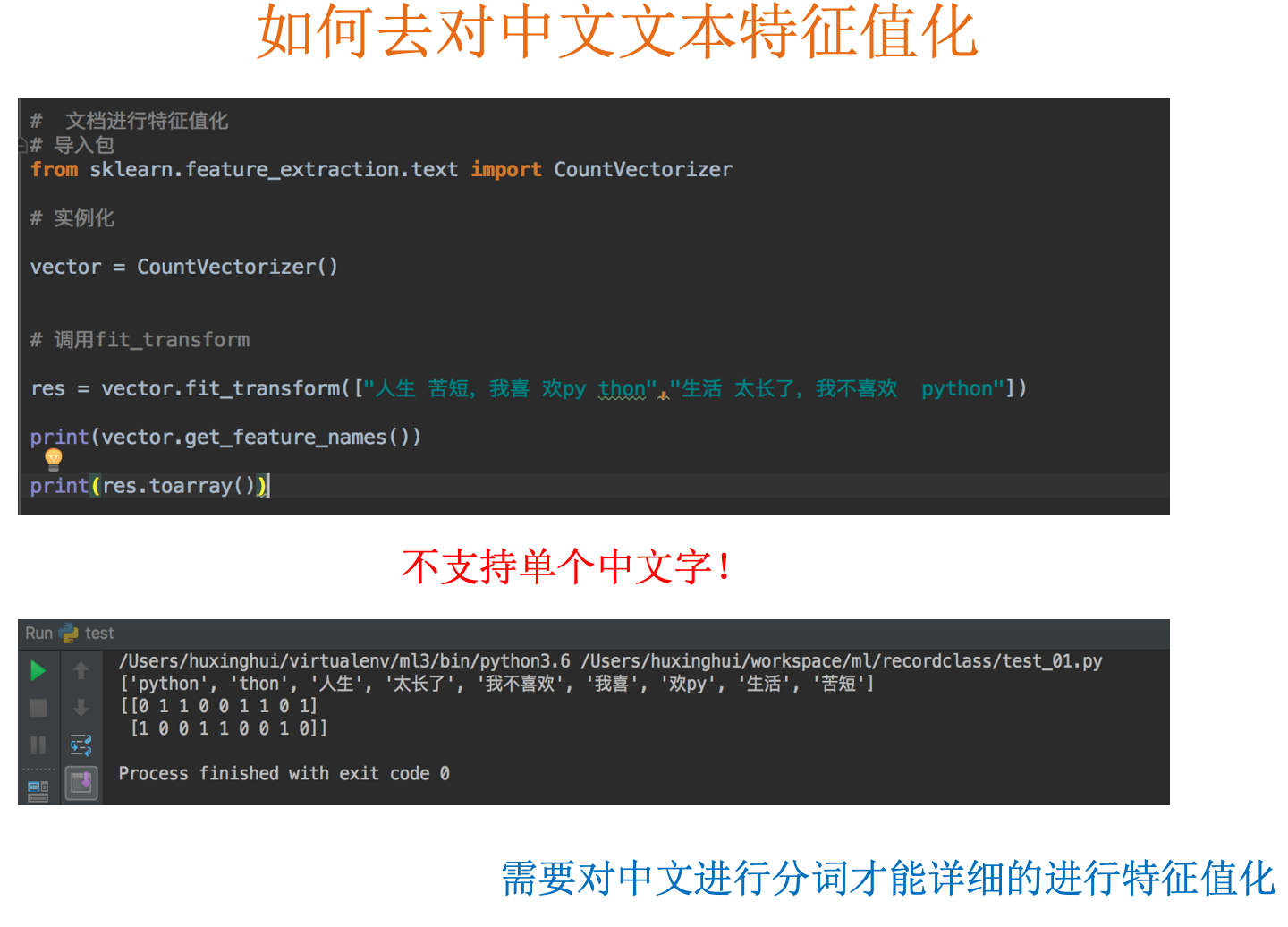
1
2
3
4
5
6
7
8
9
10
11
12
13
| def cutword():
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今。")
con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")
con3 = jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
# 吧列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3
|

# 1.3 数据的特征预处理

# 单个特征
(1)归一化
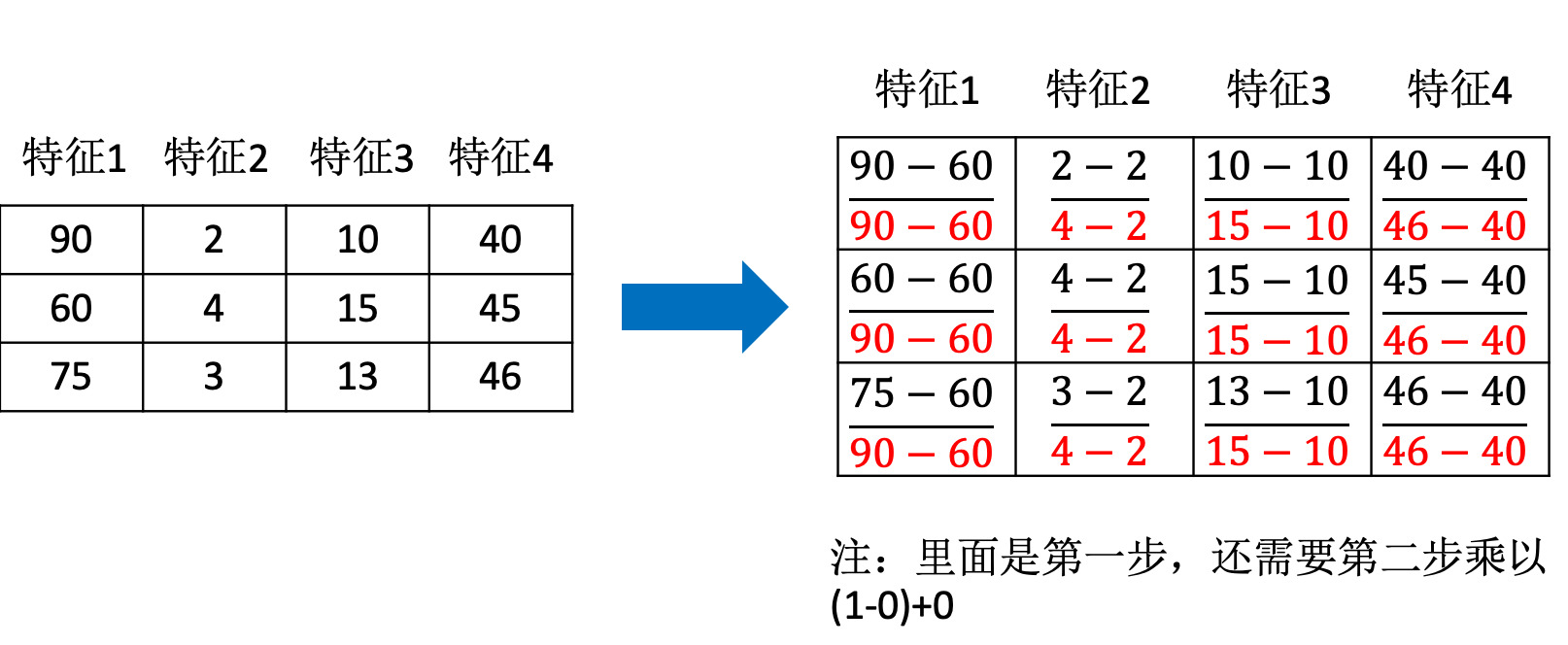
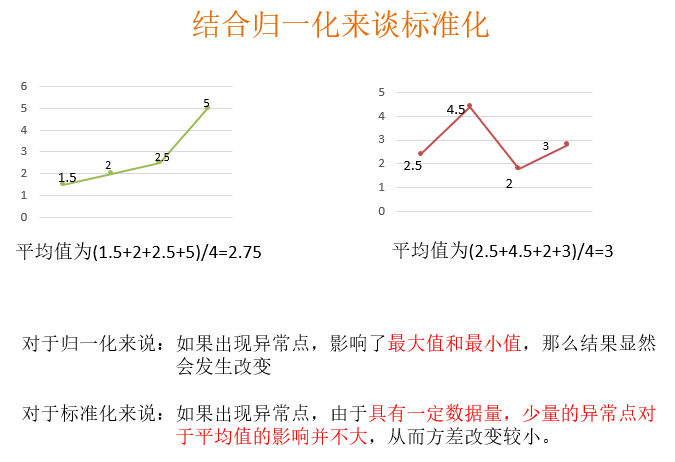
归一化首先在特征(维度)非常多的时候,可以防止某一维或某几维对数据影响过大,也是为了把不同来源的数据统一到一个参考区间下,这样比较起来才有意义,其次可以程序可以运行更快。 例如:一个人的身高和体重两个特征,假如体重 50kg,身高 175cm,由于两个单位不一样,数值大小不一样。如果比较两个人的体型差距时,那么身高的影响结果会比较大,k- 临近算法会有这个距离公式。
min-max 方法
常用的方法是通过对原始数据进行线性变换把数据映射到 [0,1] 之间,变换的函数为:
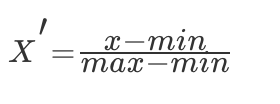

其中 min 是样本中最小值,max 是样本中最大值,注意在数据流场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
sklearn.preprocessing.MinMaxScaler(feature_range=(0,1)…)
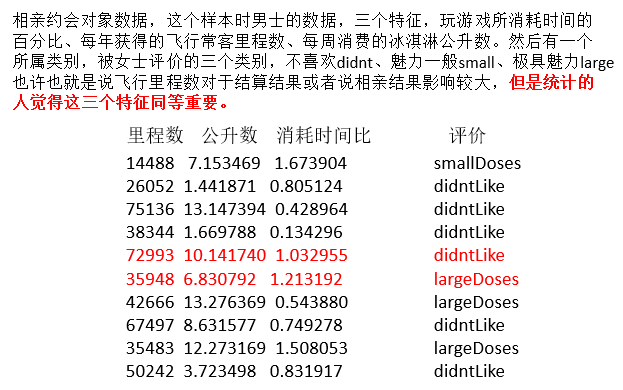
这里我们使用相亲约会对象数据在 MatchData.txt,这个样本时男士的数据,三个特征,玩游戏所消耗时间的百分比、每年获得的飞行常客里程数、每周消费的冰淇淋公升数。然后有一个 所属类别,被女士评价的三个类别,不喜欢、魅力一般、极具魅力。 首先导入数据进行矩阵转换处理.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import numpy as np
def data_matrix(file_name):
"""
将文本转化为matrix
:param file_name: 文件名
:return: 数据矩阵
"""
fr = open(file_name)
array_lines = fr.readlines()
number_lines = len(array_lines)
return_mat = zeros((number_lines, 3))
# classLabelVector = []
index = 0
for line in array_lines:
line = line.strip()
list_line = line.split('\t')
return_mat[index,:] = list_line[0:3]
# if(listFromLine[-1].isdigit()):
# classLabelVector.append(int(listFromLine[-1]))
# else:
# classLabelVector.append(love_dictionary.get(listFromLine[-1]))
# index += 1
return return_mat
|
输出结果为
1
2
3
4
5
6
7
| [[ 4.09200000e+04 8.32697600e+00 9.53952000e-01]
[ 1.44880000e+04 7.15346900e+00 1.67390400e+00]
[ 2.60520000e+04 1.44187100e+00 8.05124000e-01]
...,
[ 2.65750000e+04 1.06501020e+01 8.66627000e-01]
[ 4.81110000e+04 9.13452800e+00 7.28045000e-01]
[ 4.37570000e+04 7.88260100e+00 1.33244600e+00]]
|
我们查看数据集会发现,有的数值大到几万,有的才个位数,同样如果计算两个样本之间的距离时,其中一个影响会特别大。也就是说飞行里程数对于结算结果或者说相亲结果影响较大,但是统计的人觉得这三个特征同等重要,所以需要将数据进行这样的处理。
这样每个特征任意的范围将变成 [0,1] 的区间内的值,或者也可以根据需求处理到 [-1,1] 之间,我们再定义一个函数,进行这样的转换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| def feature_normal(data_set):
"""
特征归一化
:param data_set:
:return:
"""
# 每列最小值
min_vals = data_set.min(0)
# 每列最大值
max_vals = data_set.max(0)
ranges = max_vals - min_vals
norm_data = np.zeros(np.shape(data_set))
# 得出行数
m = data_set.shape[0]
# 矩阵相减
norm_data = data_set - np.tile(min_vals, (m,1))
# 矩阵相除
norm_data = norm_data/np.tile(ranges, (m, 1)))
return norm_data
|
输出结果为
1
2
3
4
5
6
7
| [[ 0.44832535 0.39805139 0.56233353]
[ 0.15873259 0.34195467 0.98724416]
[ 0.28542943 0.06892523 0.47449629]
...,
[ 0.29115949 0.50910294 0.51079493]
[ 0.52711097 0.43665451 0.4290048 ]
[ 0.47940793 0.3768091 0.78571804]]
|
这样得出的结果都非常相近,这样的数据可以直接提供测试验证了。
注意在特定场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
- min-max 的 scikit-learn 处理
scikit-learn.preprocessing 中的类 MinMaxScaler,将数据矩阵缩放到 [0,1] 之间
1
2
3
4
5
6
7
8
9
10
| >>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
...
>>> min_max_scaler = preprocessing.MinMaxScaler()
>>> X_train_minmax = min_max_scaler.fit_transform(X_train)
>>> X_train_minmax
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]])
|
(3)标准化
特点:通过对原始数据进行变换把数据变换到均值为 0,方差为 1 范围内。
常用的方法是 z-score 标准化,经过处理后的数据均值为 0,标准差为 1,处理方法是:
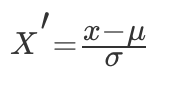

其中μ是样本的均值,σ是样本的标准差,它们可以通过现有的样本进行估计,在已有的样本足够多的情况下比较稳定,适合嘈杂的数据场景。
sklearn 中提供了 StandardScalar 类实现列标准化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| In [2]: import numpy as np
In [3]: X_train = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])
In [4]: from sklearn.preprocessing import StandardScaler
In [5]: std = StandardScaler()
In [6]: X_train_std = std.fit_transform(X_train)
In [7]: X_train_std
Out[7]:
array([[ 0. , -1.22474487, 1.33630621],
[ 1.22474487, 0. , -0.26726124],
[-1.22474487, 1.22474487, -1.06904497]])
|
(3)缺失值
由于各种原因,许多现实世界的数据集包含缺少的值,通常编码为空白,NaN 或其他占位符。然而,这样的数据集与 scikit 的分类器不兼容,它们假设数组中的所有值都是数字,并且都具有和保持含义。使用不完整数据集的基本策略是丢弃包含缺失值的整个行和/或列。然而,这是以丢失可能是有价值的数据(即使不完整)的代价。更好的策略是估算缺失值,即从已知部分的数据中推断它们。
(1) 填充缺失值 使用 sklearn.preprocessing 中的 Imputer 类进行数据的填充 (旧 API)
新:from sklearn.impute import SimpleImputer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| class Imputer(sklearn.base.BaseEstimator, sklearn.base.TransformerMixin)
"""
用于完成缺失值的补充
:param param missing_values: integer or "NaN", optional (default="NaN")
丢失值的占位符,对于编码为np.nan的缺失值,使用字符串值“NaN”
:param strategy: string, optional (default="mean")
插补策略
如果是“平均值”,则使用沿轴的平均值替换缺失值
如果为“中位数”,则使用沿轴的中位数替换缺失值
如果“most_frequent”,则使用沿轴最频繁的值替换缺失
:param axis: integer, optional (default=0)
插补的轴
如果axis = 0,则沿列排列
如果axis = 1,则沿行排列
"""
>>> import numpy as np
>>> from sklearn.impute import SimpleImputer
>>> imp = Imputer(missing_values='NaN', strategy='mean')
>>> imp.fit([[1, 2], [np.nan, 3], [7, 6]])
Imputer(axis=0, copy=True, missing_values='NaN', strategy='mean', verbose=0)
>>> X = [[np.nan, 2], [6, np.nan], [7, 6]]
>>> print(imp.transform(X))
[[ 4. 2. ]
[ 6. 3.666...]
[ 7. 6. ]]
|
# 多个特征
# 降维
高维度数据容易出现的问题: 特征之间通常是线性相关的。
PCA(Principal component analysis),主成分分析。特点是保存数据集中对方差影响最大的那些特征,PCA 极其容易受到数据中特征范围影响,所以在运用 PCA 前一定要做特征标准化,这样才能保证每维度特征的重要性等同。
目的:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
作用:可以削减回归分析或者聚类分析中特征的数量
sklearn.decomposition.PCA

1
2
3
4
5
6
7
8
9
10
11
12
| class PCA(sklearn.decomposition.base)
"""
主成成分分析
:param n_components: int, float, None or string
这个参数可以帮我们指定希望PCA降维后的特征维度数目。最常用的做法是直接指定降维到的维度数目,此时n_components是一个大于1的整数。
我们也可以用默认值,即不输入n_components,此时n_components=min(样本数,特征数)
:param whiten: bool, optional (default False)
判断是否进行白化。所谓白化,就是对降维后的数据的每个特征进行归一化。对于PCA降维本身来说一般不需要白化,如果你PCA降维后有后续的数据处理动作,可以考虑白化,默认值是False,即不进行白化
:param svd_solver:
选择一个合适的SVD算法来降维,一般来说,使用默认值就够了。
"""
|
通过一个例子来看
1
2
3
4
5
6
7
8
9
| import numpy as np
from sklearn.decomposition import PCA
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
pca = PCA(n_components=2)
pca.fit(X)
PCA(copy=True, iterated_power='auto', n_components=2, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)
print(pca.explained_variance_ratio_)
# [ 0.99244... 0.00755...]
|
# 1.4 数据的特征选择
降维本质上是从一个维度空间映射到另一个维度空间,特征的多少别没有减少,当然在映射的过程中特征值也会相应的变化。举个例子,现在的特征是 1000 维,我们想要把它降到 500 维。降维的过程就是找个一个从 1000 维映射到 500 维的映射关系。原始数据中的 1000 个特征,每一个都对应着降维后的 500 维空间中的一个值。假设原始特征中有个特征的值是 9,那么降维后对应的值可能是 3。而对于特征选择来说,有很多方法:
- Filter(过滤式):VarianceThreshold
- Embedded(嵌入式):正则化、决策树
- Wrapper(包裹式)
其中过滤式的特征选择后,数据本身不变,而数据的维度减少。而嵌入式的特征选择方法也会改变数据的值,维度也改变。Embedded 方式是一种自动学习的特征选择方法,后面讲到具体的方法的时候就能理解了。
特征选择主要有两个功能:
(1)减少特征数量,降维,使模型泛化能力更强,减少过拟合
(2)增强特征和特征值之间的理解
sklearn.feature_selection
去掉取值变化小的特征(删除低方差特征)
VarianceThreshold 是特征选择中的一项基本方法。它会移除所有方差不满足阈值的特征。默认设置下,它将移除所有方差为 0 的特征,即那些在所有样本中数值完全相同的特征。

假设我们要移除那些超过 80% 的数据都为 1 或 0 的特征:
1
2
3
4
5
6
7
8
| VarianceThreshold(threshold = 0.0)
删除所有低方差特征
Variance.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:训练集差异低于threshold的特征将被删除。
默认值是保留所有非零方差特征,即删除所有样本
中具有相同值的特征。
|
1
2
3
4
5
6
7
8
9
10
| from sklearn.feature_selection import VarianceThreshold
X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]]
sel = VarianceThreshold(threshold=(.8 * (1 - .8)))
sel.fit_transform(X)
array([[0, 1],
[1, 0],
[0, 0],
[1, 1],
[1, 0],
[1, 1]])
|
# 2. Sklearn 数据集与机器学习组成
# 机器学习组成:模型、策略、优化
《统计机器学习》中指出:机器学习=模型 + 策略 + 算法。其实机器学习可以表示为:Learning= Representation+Evalution+Optimization。我们就可以将这样的表示和李航老师的说法对应起来。机器学习主要是由三部分组成,即:表示 (模型)、评价 (策略) 和优化 (算法)。
表示 (或者称为:模型):Representation
表示主要做的就是建模,故可以称为模型。模型要完成的主要工作是转换:将实际问题转化成为计算机可以理解的问题,就是我们平时说的建模。类似于传统的计算机学科中的算法,数据结构,如何将实际的问题转换成计算机可以表示的方式。这部分可以见“简单易学的机器学习算法”。给定数据,我们怎么去选择对应的问题去解决,选择正确的已有的模型是重要的一步。
评价 (或者称为:策略):Evalution
评价的目标是判断已建好的模型的优劣。对于第一步中建好的模型,评价是一个指标,用于表示模型的优劣。这里就会是一些评价的指标以及一些评价函数的设计。在机器学习中会有针对性的评价指标。
优化:Optimization
优化的目标是评价的函数,我们是希望能够找到最好的模型,也就是说评价最高的模型。
# 开发机器学习应用程序的步骤
(1)收集数据
我们可以使用很多方法收集样本护具,如:制作网络爬虫从网站上抽取数据、从 RSS 反馈或者 API 中得到信息、设备发送过来的实测数据。
(2)准备输入数据
得到数据之后,还必须确保数据格式符合要求。
(3)分析输入数据
这一步的主要作用是确保数据集中没有垃圾数据。如果是使用信任的数据来源,那么可以直接跳过这个步骤
(4)训练算法
机器学习算法从这一步才真正开始学习。如果使用无监督学习算法,由于不存在目标变量值,故而也不需要训练算法,所有与算法相关的内容在第(5)步
(5)测试算法
这一步将实际使用第(4)步机器学习得到的知识信息。当然在这也需要评估结果的准确率,然后根据需要重新训练你的算法
(6)使用算法
转化为应用程序,执行实际任务。以检验上述步骤是否可以在实际环境中正常工作。如果碰到新的数据问题,同样需要重复执行上述的步骤
# 2.1 Scikit-learn 数据集
我们将介绍 sklearn 中的数据集类,模块包括用于加载数据集的实用程序,包括加载和获取流行参考数据集的方法。它还具有一些人工数据生成器。
# sklearn.datasets
(1)datasets.load_*()
获取小规模数据集,数据包含在 datasets 里
(2)datasets.fetch_*()
获取大规模数据集,需要从网络上下载,函数的第一个参数是 data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/,要修改默认目录,可以修改环境变量 SCIKIT_LEARN_DATA

(3)datasets.make_*()
本地生成数据集
load*和 fetch* 函数返回的数据类型是 datasets.base.Bunch,本质上是一个 dict,它的键值对可用通过对象的属性方式访问。主要包含以下属性:
- data:特征数据数组,是 n_samples * n_features 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名
- target_names:标签名
数据集目录可以通过 datasets.get_data_home() 获取,clear_data_home(data_home=None) 删除所有下载数据
(4)datasets.get_data_home(data_home=None)
返回 scikit 学习数据目录的路径。这个文件夹被一些大的数据集装载器使用,以避免下载数据。默认情况下,数据目录设置为用户主文件夹中名为“scikit_learn_data”的文件夹。或者,可以通过“SCIKIT_LEARN_DATA”环境变量或通过给出显式的文件夹路径以编程方式设置它。’〜’ 符号扩展到用户主文件夹。如果文件夹不存在,则会自动创建。
(5)sklearn.datasets.clear_data_home(data_home=None)
删除存储目录中的数据
# 获取小数据集
用于分类
- sklearn.datasets.load_iris
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| class sklearn.datasets.load_iris(return_X_y=False)
"""
加载并返回虹膜数据集
:param return_X_y: 如果为True,则返回而不是Bunch对象,默认为False
:return: Bunch对象,如果return_X_y为True,那么返回tuple,(data,target)
"""
In [12]: from sklearn.datasets import load_iris
...: data = load_iris()
...:
In [13]: data.target
Out[13]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
In [14]: data.feature_names
Out[14]:
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
In [15]: data.target_names
Out[15]:
array(['setosa', 'versicolor', 'virginica'],
dtype='|S10')
In [17]: data.targetspan>
Out[17]: array([0, 0, 2])
|
| 名称 | 数量 |
|---|
| 类别 | 3 |
| 特征 | 4 |
| 样本数量 | 150 |
| 每个类别数量 | 50 |
- sklearn.datasets.load_digits
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| class sklearn.datasets.load_digits(n_class=10, return_X_y=False)
"""
加载并返回数字数据集
:param n_class: 整数,介于0和10之间,可选(默认= 10,要返回的类的数量
:param return_X_y: 如果为True,则返回而不是Bunch对象,默认为False
:return: Bunch对象,如果return_X_y为True,那么返回tuple,(data,target)
"""
In [20]: from sklearn.datasets import load_digits
In [21]: digits = load_digits()
In [22]: print(digits.data.shape)
(1797, 64)
In [23]: digits.target
Out[23]: array([0, 1, 2, ..., 8, 9, 8])
In [24]: digits.target_names
Out[24]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [25]: digits.images
Out[25]:
array([[[ 0., 0., 5., ..., 1., 0., 0.],
[ 0., 0., 13., ..., 15., 5., 0.],
[ 0., 3., 15., ..., 11., 8., 0.],
...,
[ 0., 4., 11., ..., 12., 7., 0.],
[ 0., 2., 14., ..., 12., 0., 0.],
[ 0., 0., 6., ..., 0., 0., 0.]],
[[ 0., 0., 10., ..., 1., 0., 0.],
[ 0., 2., 16., ..., 1., 0., 0.],
[ 0., 0., 15., ..., 15., 0., 0.],
...,
[ 0., 4., 16., ..., 16., 6., 0.],
[ 0., 8., 16., ..., 16., 8., 0.],
[ 0., 1., 8., ..., 12., 1., 0.]]])
|
用于回归
- sklearn.datasets.load_boston
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| class sklearn.datasets.load_boston(return_X_y=False)
"""
加载并返回波士顿房价数据集
:param return_X_y: 如果为True,则返回而不是Bunch对象,默认为False
:return: Bunch对象,如果return_X_y为True,那么返回tuple,(data,target)
"""
In [34]: from sklearn.datasets import load_boston
In [35]: boston = load_boston()
In [36]: boston.data.shape
Out[36]: (506, 13)
In [37]: boston.feature_names
Out[37]:
array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'],
dtype='|S7')
In [38]:
|
- sklearn.datasets.load_diabetes
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| class sklearn.datasets.load_diabetes(return_X_y=False)
"""
加载和返回糖尿病数据集
:param return_X_y: 如果为True,则返回而不是Bunch对象,默认为False
:return: Bunch对象,如果return_X_y为True,那么返回tuple,(data,target)
"""
In [13]: from sklearn.datasets import load_diabetes
In [14]: diabetes = load_diabetes()
In [15]: diabetes.data
Out[15]:
array([[ 0.03807591, 0.05068012, 0.06169621, ..., -0.00259226,
0.01990842, -0.01764613],
[-0.00188202, -0.04464164, -0.05147406, ..., -0.03949338,
-0.06832974, -0.09220405],
[ 0.08529891, 0.05068012, 0.04445121, ..., -0.00259226,
0.00286377, -0.02593034],
...,
[ 0.04170844, 0.05068012, -0.01590626, ..., -0.01107952,
-0.04687948, 0.01549073],
[-0.04547248, -0.04464164, 0.03906215, ..., 0.02655962,
0.04452837, -0.02593034],
[-0.04547248, -0.04464164, -0.0730303 , ..., -0.03949338,
-0.00421986, 0.00306441]])
|
| 名称 | 数量 |
|---|
| 目标范围 | 25-346 |
| 特征 | 10 |
| 样本数量 | 442 |
# 获取大数据集
- sklearn.datasets.fetch_20newsgroups
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| class sklearn.datasets.fetch_20newsgroups(data_home=None, subset='train', categories=None, shuffle=True, random_state=42, remove=(), download_if_missing=True)
"""
加载20个新闻组数据集中的文件名和数据
:param subset: 'train'或者'test','all',可选,选择要加载的数据集:训练集的“训练”,测试集的“测试”,两者的“全部”,具有洗牌顺序
:param data_home: 可选,默认值:无,指定数据集的下载和缓存文件夹。如果没有,所有scikit学习数据都存储在'〜/ scikit_learn_data'子文件夹中
:param categories: 无或字符串或Unicode的集合,如果没有(默认),加载所有类别。如果不是无,要加载的类别名称列表(忽略其他类别)
:param shuffle: 是否对数据进行洗牌
:param random_state: numpy随机数生成器或种子整数
:param download_if_missing: 可选,默认为True,如果False,如果数据不在本地可用而不是尝试从源站点下载数据,则引发IOError
:param remove: 元组
"""
In [29]: from sklearn.datasets import fetch_20newsgroups
In [30]: data_test = fetch_20newsgroups(subset='test',shuffle=True, random_sta
...: te=42)
In [31]: data_train = fetch_20newsgroups(subset='train',shuffle=True, random_s
...: tate=42)
|
- sklearn.datasets.fetch_20newsgroups_vectorized
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class sklearn.datasets.fetch_20newsgroups_vectorized(subset='train', remove=(), data_home=None)
"""
加载20个新闻组数据集并将其转换为tf-idf向量,这是一个方便的功能; 使用sklearn.feature_extraction.text.Vectorizer的默认设置完成tf-idf 转换。对于更高级的使用(停止词过滤,n-gram提取等),将fetch_20newsgroup与自定义Vectorizer或CountVectorizer组合在一起
:param subset: 'train'或者'test','all',可选,选择要加载的数据集:训练集的“训练”,测试集的“测试”,两者的“全部”,具有洗牌顺序
:param data_home: 可选,默认值:无,指定数据集的下载和缓存文件夹。如果没有,所有scikit学习数据都存储在'〜/ scikit_learn_data'子文件夹中
:param remove: 元组
"""
In [57]: from sklearn.datasets import fetch_20newsgroups_vectorized
In [58]: bunch = fetch_20newsgroups_vectorized(subset='all')
In [59]: from sklearn.utils import shuffle
In [60]: X, y = shuffle(bunch.data, bunch.target)
...: offset = int(X.shape[0] * 0.8)
...: X_train, y_train = X[:offset], y[:offset]
...: X_test, y_test = X[offset:], y[offset:]
...:
|
# 获取本地生成数据
生成本地分类数据:
1
2
| from sklearn.datasets.samples_generator import make_classification
X,y= datasets.make_classification(n_samples=100000, n_features=20,n_informative=2, n_redundant=10,random_state=42)
|
生成本地回归数据:
- sklearn.datasets.make_regression
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| class make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)
"""
生成用于回归的数据集
:param n_samples:int,optional(default = 100),样本数量
:param n_features:int,optional(default = 100),特征数量
:param coef:boolean,optional(default = False),如果为True,则返回底层线性模型的系数
:param random_state:int,RandomState实例或无,可选(默认=无)
如果int,random_state是随机数生成器使用的种子; 如果RandomState的实例,random_state是随机数生成器; 如果没有,随机数生成器所使用的RandomState实例np.random
:return :X,特征数据集;y,目标值
"""
from sklearn.datasets.samples_generator import make_regression
X, y = make_regression(n_samples=200, n_features=5000, random_state=42)
|
# 2.2 模型的选择
算法是核心,数据和计算是基础。这句话很好的说明了机器学习中算法的重要性。那么我们开看下机器学习的几种分类:
- 监督学习
- 分类 k- 近邻算法、决策树、贝叶斯、逻辑回归 (LR)、支持向量机 (SVM)
- 回归 线性回归、岭回归
- 标注 隐马尔可夫模型 (HMM)
- 无监督学习
# 如何选择合适的算法模型
在解决问题的时候,必须考虑下面两个问题:一、使用机器学习算法的目的,想要算法完成何种任务,比如是预测明天下雨的概率是对投票者按照兴趣分组;二、需要分析或者收集的数据时什么
首先考虑使用机器学习算法的目的。如果想要预测目标变量的值,则可以选择监督学习算法,否则可以选择无监督学习算法,确定选择监督学习算法之后,需要进一步确定目标变量类型,如果目标变量是离散型,如是/否、1/2/3,A/B/C/或者红/黑/黄等,则可以选择分类算法;如果目标变量是连续的数值,如 0.0~100.0、-999~999 等,则需要选择回归算法
如果不想预测目标变量的值,则可以选择无监督算法。进一步分析是否需要将数据划分为离散的组。如果这是唯一的需求,则使用聚类算法。
当然在大多数情况下,上面给出的选择办法都能帮助读者选择恰当的机器学习算法,但这也并非已成不变。也有分类算法可以用于回归。
其次考虑的是数据问题,我们应该充分了解数据,对实际数据了解的越充分,越容易创建符合实际需求的应用程序,主要应该了解数据的一下特性:特征值是离散型变量 还是 连续型变量 ,特征值中是否存在缺失的值,何种原因造成缺失值,数据中是够存在异常值,某个特征发生的频率如何,等等。充分了解上面提到的这些数据特性可以缩短选择机器学习算法的时间。
# 监督学习中三类问题的解释
(1)分类问题 分类是监督学习的一个核心问题,在监督学习中,当输出变量取有限个离散值时,预测问题变成为分类问题。这时,输入变量可以是离散的,也可以是连续的。监督学习从数据中学习一个分类模型活分类决策函数,称为分类器。分类器对新的输入进行输出的预测,称为分类。最基础的便是二分类问题,即判断是非,从两个类别中选择一个作为预测结果;除此之外还有多酚类的问题,即在多于两个类别中选择一个。
分类问题包括学习和分类两个过程,在学习过程中,根据已知的训练数据集利用有效的学习方法学习一个分类器,在分类过程中,利用学习的分类器对新的输入实例进行分类。图中 (X1,Y1),(X2,Y2)…都是训练数据集,学习系统有训练数据学习一个分类器 P(Y|X) 或 Y=f(X); 分类系统通过学习到的分类器对于新输入的实例子 Xn+1 进行分类,即预测术其输出的雷标记 Yn+1
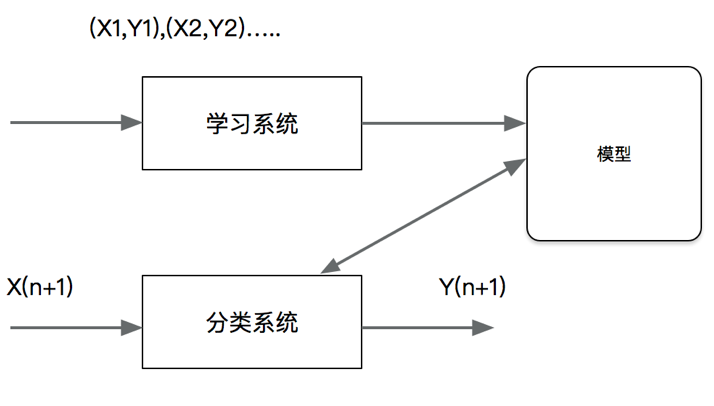
分类在于根据其特性将数据“分门别类”,所以在许多领域都有广泛的应用。例如,在银行业务中,可以构建一个客户分类模型,按客户按照贷款风险的大小进行分类;在网络安全领域,可以利用日志数据的分类对非法入侵进行检测;在图像处理中,分类可以用来检测图像中是否有人脸出现;在手写识别中,分类可以用于识别手写的数字;在互联网搜索中,网页的分类可以帮助网页的抓取、索引和排序。
即一个分类应用的例子,文本分类。这里的文本可以是新闻报道、网页、电子邮件、学术论文。类别往往是关于文本内容的。例如政治、体育、经济等;也有关于文本特点的,如正面意见、反面意见;还可以根据应用确定,如垃圾邮件、非垃圾邮件等。文本分类是根据文本的特征将其划分到已有的类中。输入的是文本的特征向量,输出的是文本的类别。通常把文本的单词定义出现取值是 1,否则是 0;也可以是多值的,,表示单词在文本中出现的频率。直观地,如果“股票”“银行““货币”这些词出现很多,这个文本可能属于经济学,如果“网球””比赛“”运动员“这些词频繁出现,这个文本可能属于体育类。
(2)回归问题
回归是监督学习的另一个重要问题。回归用于预测输入变量和输出变量之间的关系,特别是当初如变量的值发生变化时,输出变量的值随之发生的变化。回归模型正式表示从输入到输出变量之间映射的函数。回归稳日的学习等价与函数拟合:选择一条函数曲线使其更好的拟合已知数据且很好的预测位置数据
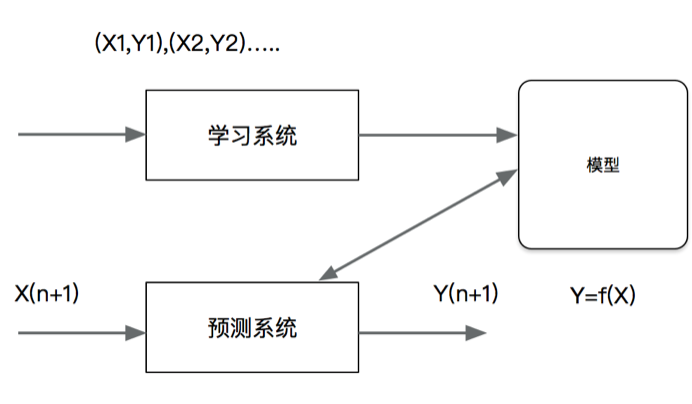
回归问题按照输入变量的个数,分为一元回归和多元回归;按照输入变量和输出变量之间关系的类型即模型的类型,分为线性回归和非线性回归。
许多领域的任务都可以形式化为回归问题,比如,回归可以用于商务领域,作为市场趋势预测、产品质量管理、客户满意度调查、偷袭风险分析的工具。
(3)标注问题
标注也是一个监督学习问题。可以认为标注问题是分类问题的一个推广,标注问题又是更复杂的结构预测问题的简单形式。标注问题的输入是一个观测序列,输出是一个标记序列或状态序列。标注问题在信息抽取、自然语言处理等领域广泛应用,是这些领域的基本问题。例如,自然语言处理的词性标注就是一个典型的标注,即对一个单词序列预测其相应的词性标记序
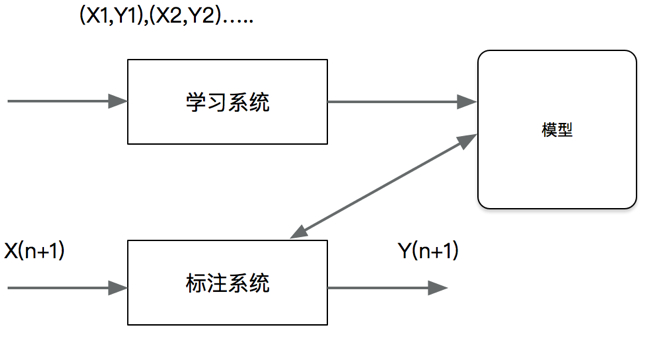
当然我们主要关注的是分类和回归问题,并且标注问题的算法复杂
# 2.3 模型检验 - 交叉验证
一般在进行模型的测试时,我们会将数据分为训练集和测试集。在给定的样本空间中,拿出大部分样本作为训练集来训练模型,剩余的小部分样本使用刚建立的模型进行预测。
# 训练集与测试集
训练集与测试集的分割可以使用 cross_validation 中的 train_test_split 方法,大部分的交叉验证迭代器都内建一个划分数据前进行数据索引打散的选项,train_test_split 方法内部使用的就是交叉验证迭代器。默认不会进行打散,包括设置 cv=some_integer(直接)k 折叠交叉验证的 cross_val_score 会返回一个随机的划分。如果数据集具有时间性,千万不要打散数据再划分!
- sklearn.cross_validation.train_test_split
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| def train_test_split(*arrays,**options)
"""
:param arrays:允许的输入是列表,数字阵列
:param test_size:float,int或None(默认为无),如果浮点数应在0.0和1.0之间,并且表示要包括在测试拆分中的数据集的比例。如果int,表示测试样本的绝对数
:param train_size:float,int或None(默认为无),如果浮点数应在0.0到1.0之间,表示数据集包含在列车拆分中的比例。如果int,表示列车样本的绝对数
:param random_state:int或RandomState,用于随机抽样的伪随机数发生器状态,参数 random_state 默认设置为 None,这意为着每次打散都是不同的。
"""
from sklearn.cross_validation import train_test_split
from sklearn import datasets
iris = datasets.load_iris()
print iris.data.shape,iris.target.shape
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.4, random_state=42)
print X_train.shape,y_train.shape
print X_test.shape,y_test.shape
|
上面的方式也有局限。因为只进行一次测试,并不一定能代表模型的真实准确率。因为,模型的准确率和数据的切分有关系,在数据量不大的情况下,影响尤其突出。所以还需要一个比较好的解决方案。
模型评估中,除了训练数据和测试数据,还会涉及到验证数据。使用训练数据与测试数据进行了交叉验证,只有这样训练出的模型才具有更可靠的准确率,也才能期望模型在新的、未知的数据集上,能有更好的表现。这便是模型的推广能力,也即泛化能力的保证。
# Holdout Method
评估模型泛化能力的典型方法是 holdout 交叉验证 (holdout cross validation)。holdout 方法很简单,我们只需要将原始数据集分割为训练集和测试集,前者用于训练模型,后者用于评估模型的性能。一般来说,Holdout 验证并非一种交叉验证,因为数据并没有交叉使用。 随机从最初的样本中选出部分,形成交叉验证数据,而剩余的就当做训练数据。 一般来说,少于原本样本三分之一的数据被选做验证数据。所以这种方法得到的结果其实并不具有说服性
# K- 折交叉验证
K 折交叉验证,初始采样分割成 K 个子样本,一个单独的子样本被保留作为验证模型的数据,其他 K-1 个样本用来训练。交叉验证重复 K 次,每个子样本验证一次,平均 K 次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10 折交叉验证是最常用的。
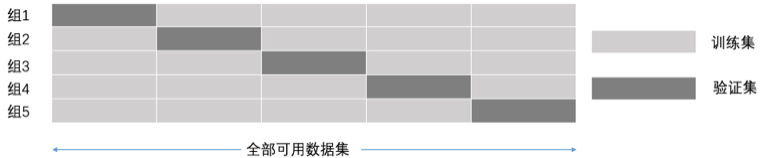
例如 5 折交叉验证,全部可用数据集分成五个集合,每次迭代都选其中的 1 个集合数据作为验证集,另外 4 个集合作为训练集,经过 5 组的迭代过程。交叉验证的好处在于,可以保证所有数据都有被训练和验证的机会,也尽最大可能让优化的模型性能表现的更加可信。
使用交叉验证的最简单的方法是在估计器和数据集上使用 cross_val_score 函数。
- sklearn.cross_validation.cross_val_score
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| def cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
"""
:param estimator:模型估计器
:param X:特征变量集合
:param y:目标变量
:param cv:int,使用默认的3折交叉验证,整数指定一个(分层)KFold中的折叠数
:return :预估系数
"""
from sklearn.cross_validation import cross_val_score
diabetes = datasets.load_diabetes()
X = diabetes.data[:150]
y = diabetes.target[:150]
lasso = linear_model.Lasso()
print(cross_val_score(lasso, X, y))
|
使用交叉验证方法的目的主要有 2 个:
- 从有限的学习数据中获取尽可能多的有效信息;
- 可以在一定程度上避免过拟合问题。
# 超参数搜索 - 网格搜索
通常情况下,有很多参数是需要手动指定的(如 k- 近邻算法中的 K 值),
这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组
合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建
立模型。

sklearn.model_selection.GridSearchCV

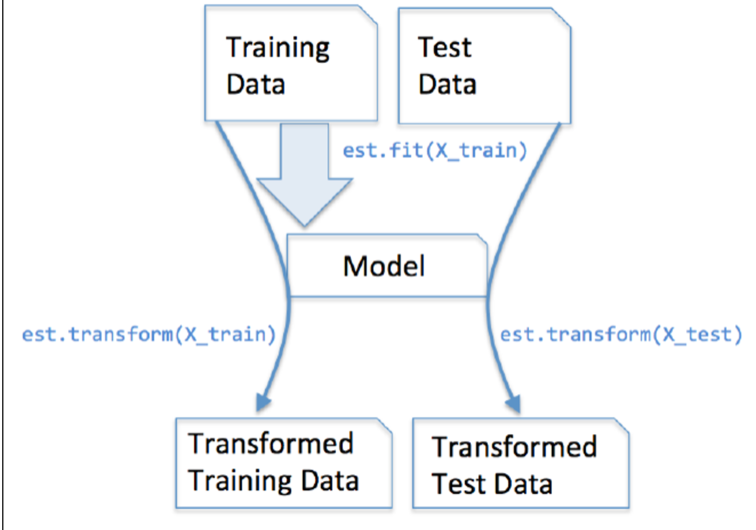
# 2.4 Estimator 的工作流程

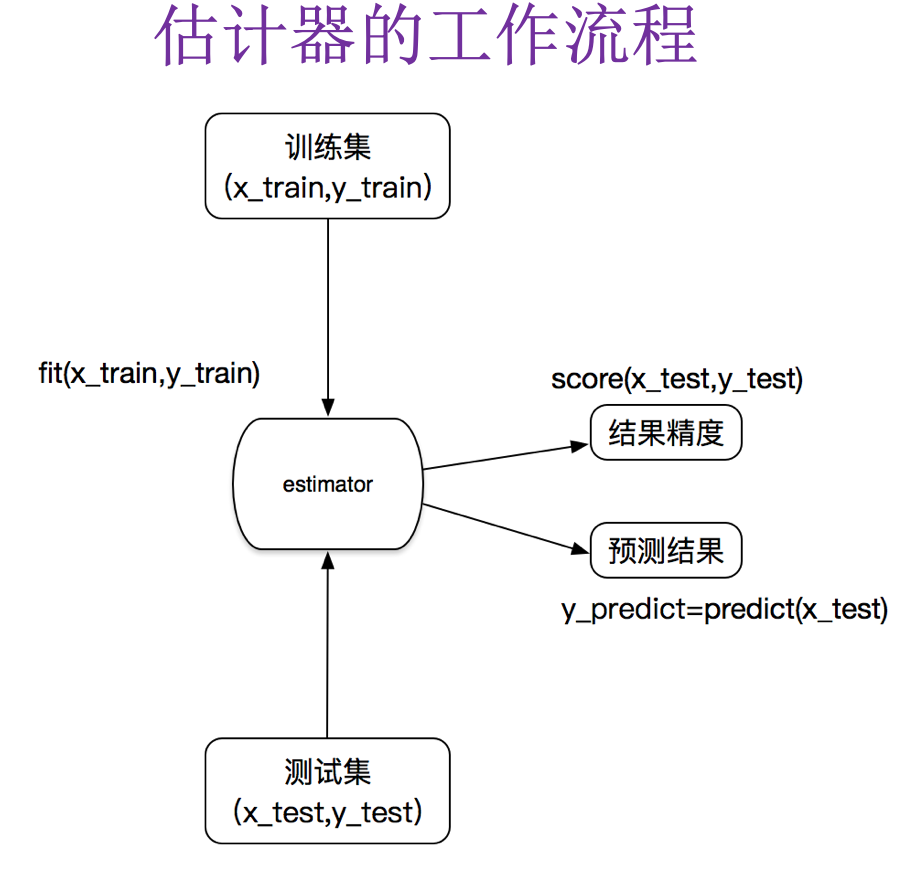
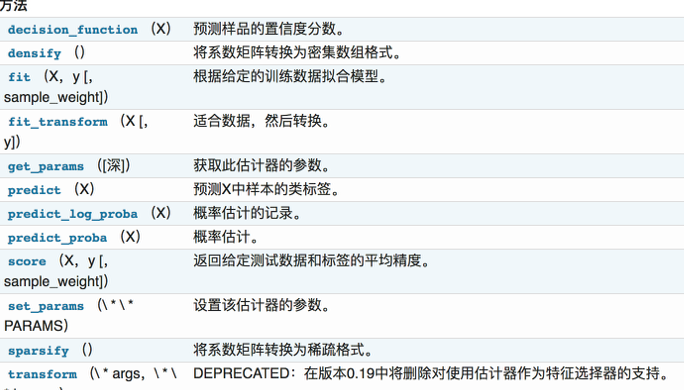
在 sklearn 中,估计器 (estimator) 是一个重要的角色,分类器和回归器都属于 estimator。在估计器中有有两个重要的方法是 fit 和 transform。
- fit 方法用于从训练集中学习模型参数
- transform 用学习到的参数转换数据
# 3. Scikit-learn 的分类器算法
# 3.1 分类算法之 K- 近邻
定义:如果一个样本在特征空间中的 k 个最相似 (即特征空间中最邻近) 的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN 算法最早是由 Cover 和 Hart 提出的一种分类算法。
k- 近邻算法采用测量不同特征值之间的距离来进行分类
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高,必须指定 K 值,K 值选择不当则分类精度不能保证
使用数据范围:数值型和标称型
加快搜索速度——基于算法的改进 KDTree,API 接口里面有实现
# 一个例子弄懂 K- 近邻
电影可以按照题材分类,每个题材又是如何定义的呢?那么假如两种类型的电影,动作片和爱情片。动作片有哪些公共的特征?那么爱情片又存在哪些明显的差别呢?我们发现动作片中打斗镜头的次数较多,而爱情片中接吻镜头相对更多。当然动作片中也有一些接吻镜头,爱情片中也会有一些打斗镜头。所以不能单纯通过是否存在打斗镜头或者接吻镜头来判断影片的类别。那么现在我们有 6 部影片已经明确了类别,也有打斗镜头和接吻镜头的次数,还有一部电影类型未知。
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|
| California Man | 3 | 104 | 爱情片 |
| He’s not Really into dues | 2 | 100 | 爱情片 |
| Beautiful Woman | 1 | 81 | 爱情片 |
| Kevin Longblade | 101 | 10 | 动作片 |
| Robo Slayer 3000 | 99 | 5 | 动作片 |
| Amped II | 98 | 2 | 动作片 |
| ? | 18 | 90 | 未知 |
那么我们使用 K- 近邻算法来分类爱情片和动作片:存在一个样本数据集合,也叫训练样本集,样本个数 M 个,知道每一个数据特征与类别对应关系,然后存在未知类型数据集合 1 个,那么我们要选择一个测试样本数据中与训练样本中 M 个的距离,排序过后选出最近的 K 个,这个取值一般不大于 20 个。选择 K 个最相近数据中次数最多的分类。那么我们根据这个原则去判断未知电影的分类
| 电影名称 | 与未知电影的距离 |
|---|
| California Man | 20.5 |
| He’s not Really into dues | 18.7 |
| Beautiful Woman | 19.2 |
| Kevin Longblade | 115.3 |
| Robo Slayer 3000 | 117.4 |
| Amped II | 118.9 |
我们假设 K 为 3,那么排名前三个电影的类型都是爱情片,所以我们判定这个未知电影也是一个爱情片。那么计算距离是怎样计算的呢?

# sklearn.neighbors
sklearn.neighbors 提供监督的基于邻居的学习方法的功能,sklearn.neighbors.KNeighborsClassifier 是一个最近邻居分类器。那么 KNeighborsClassifier 是一个类,我们看一下实例化时候的参数

1
2
3
4
5
6
7
8
9
10
11
12
13
| class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1, **kwargs)**
"""
:param n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
:param algorithm:{'auto','ball_tree','kd_tree','brute'},可选用于计算最近邻居的算法:'ball_tree'将会使用 BallTree,'kd_tree'将使用 KDTree,“野兽”将使用强力搜索。'auto'将尝试根据传递给fit方法的值来决定最合适的算法。
:param n_jobs:int,可选(默认= 1),用于邻居搜索的并行作业数。如果-1,则将作业数设置为CPU内核数。不影响fit方法。
"""
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
neigh = KNeighborsClassifier(n_neighbors=3)
|
# Method
fit(X, y)
使用 X 作为训练数据拟合模型,y 作为 X 的类别值。X,y 为数组或者矩阵
1
2
3
| X = np.array([[1,1],[1,1.1],[0,0],[0,0.1]])
y = np.array([1,1,0,0])
neigh.fit(X,y)
|
kneighbors(X=None, n_neighbors=None, return_distance=True)
找到指定点集 X 的 n_neighbors 个邻居,return_distance 为 False 的话,不返回距离
1
2
3
| neigh.kneighbors(np.array(span>),return_distance= False)
neigh.kneighbors(np.array(span>),return_distance= False,an_neighbors=2)
|
predict(X)
预测提供的数据的类标签
1
| neigh.predict(np.array([[0.1,0.1],[1.1,1.1]]))
|
predict_proba(X)
返回测试数据 X 属于某一类别的概率估计
1
| neigh.predict_proba(np.array(span>))
|
# 3.2 K- 近邻算法案例分析
本案例使用最著名的”鸢尾“数据集,该数据集曾经被 Fisher 用在经典论文中,目前作为教科书般的数据样本预存在 Scikit-learn 的工具包中。

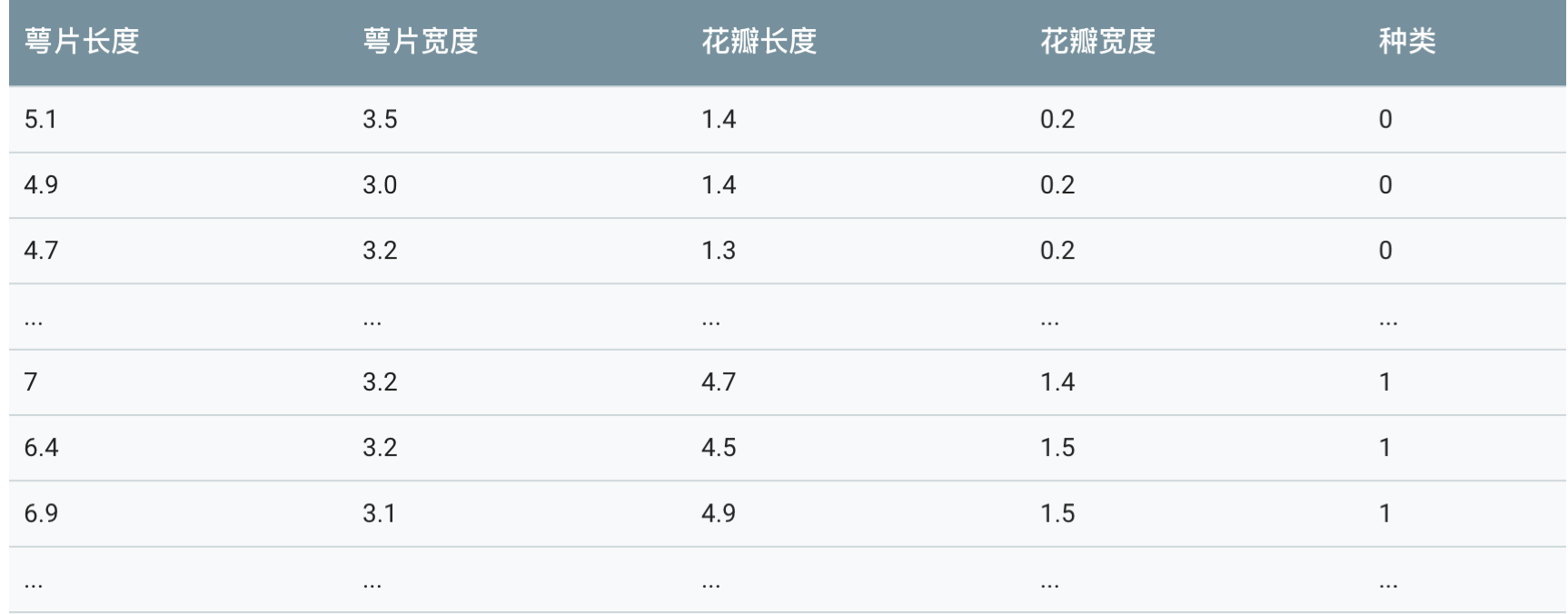
读入 Iris 数据集细节资料
1
2
3
4
5
6
7
8
9
| from sklearn.datasets import load_iris
# 使用加载器读取数据并且存入变量iris
iris = load_iris()
# 查验数据规模
iris.data.shape
# 查看数据说明(这是一个好习惯)
print iris.DESCR
|
通过上述代码对数据的查验以及数据本身的描述,我们了解到 Iris 数据集共有 150 朵鸢尾数据样本,并且均匀分布在 3 个不同的亚种;每个数据样本有总共 4 个不同的关于花瓣、花萼的形状特征所描述。由于没有制定的测试集合,因此按照惯例,我们需要对数据进行随即分割,25% 的样本用于测试,其余 75% 的样本用于模型的训练。
由于不清楚数据集的排列是否随机,可能会有按照类别去进行依次排列,这样训练样本的不均衡的,所以我们需要分割数据,已经默认有随机采样的功能。
对 Iris 数据集进行分割
1
2
| from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.25,random_state=42)
|
对特征数据进行标准化
1
2
3
4
5
| from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.fit_transform(X_test)
|
K 近邻算法是非常直观的机器学习模型,我们可以发现 K 近邻算法没有参数训练过程,也就是说,我们没有通过任何学习算法分析训练数据,而只是根据测试样本训练数据的分布直接作出分类决策。因此,K 近邻属于无参数模型中非常简单一种。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| from sklearn.datasets import load_iris
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import GridSearchCV
def knniris():
"""
鸢尾花分类
:return: None
"""
# 数据集获取和分割
lr = load_iris()
x_train, x_test, y_train, y_test = train_test_split(lr.data, lr.target, test_size=0.25)
# 进行标准化
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# estimator流程
knn = KNeighborsClassifier()
# # 得出模型
# knn.fit(x_train,y_train)
#
# # 进行预测或者得出精度
# y_predict = knn.predict(x_test)
#
# # score = knn.score(x_test,y_test)
# 通过网格搜索,n_neighbors为参数列表
param = {"n_neighbors": [3, 5, 7]}
gs = GridSearchCV(knn, param_grid=param, cv=10)
# 建立模型
gs.fit(x_train,y_train)
# print(gs)
# 预测数据
print(gs.score(x_test,y_test))
# 分类模型的精确率和召回率
# print("每个类别的精确率与召回率:",classification_report(y_test, y_predict,target_names=lr.target_names))
return None
if __name__ == "__main__":
knniris()
|
# 3.3 朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一个非常简单,但是实用性很强的分类模型。朴素贝叶斯分类器的构造基础是贝叶斯理论。

# 概率论基础
概率定义为一件事情发生的可能性。事情发生的概率可以 通过观测数据中的事件发生次数来计算,事件发生的概率等于改事件发生次数除以所有事件发生的总次数。举一些例子:
- 扔出一个硬币,结果头像朝上
- 某天是晴天
- 某个单词在未知文档中出现
我们将事件的概率记作 P(X),那么假设这一事件为 X 属于样本空间中的一个类别,那么 0≤P(X)≤1。
联合概率与条件概率
是指两件事情同时发生的概率。那么我们假设样本空间有一些天气数据:
| 编号 | 星期几 | 天气 |
|---|
| 1 | 2 | 晴天 |
| 2 | 1 | 下雨 |
| 3 | 3 | 晴天 |
| 4 | 4 | 晴天 |
| 5 | 1 | 下雨 |
| 6 | 2 | 下雪 |
| 7 | 3 | 下雪 |
那么天气被分成了三类,那么 P(X=sun)=3/7,假如说天气=下雪且星期几=2?这个概率怎么求?这个概率应该等于两件事情为真的次数除以所有事件发生 的总次数。我们可以看到只有一个样本满足天气=下雪且星期几=2,所以这个概率为 1/7。一般对于 X 和 Y 来说,对应的联合概率记为 P(XY)。
那么条件概率形如 P(X∣Y),这种格式的。表示为在 Y 发生的条件下,发生 X 的概率。假设 X 代表星期,Y 代表天气,则 P(X=3∣Y=sun) 如何求?
从表中我们可以得出,P(X=3,Y=sun)=1/7,P(Y)=3/7。
P(X=3∣Y=sun)=1/3=P(X=3,Y=sun)/P(Y)
在条件概率中,有一个重要的特性
那么则有
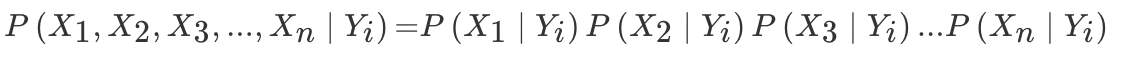
这个式子的意思是给定条件下,所有的 X 的概率为单独的 Y 条件下每个 X 发生的概率乘积,我们通过后面再继续去理解这个式子的具体含义。
贝叶斯公式
首先我们给出该公式的表示,
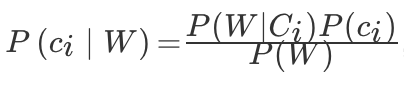 ,其中 ci 为类别,W 为特征向量。
,其中 ci 为类别,W 为特征向量。
贝叶斯公式最常用于文本分类,上式左边可以理解为给定一个文本词向量 W,那么它属于类别 ci 的概率是多少。那么式子右边分几部分,P(W∣ci) 理解为在给定类别的情况下,该文档的词向量的概率。可以通过条件概率中的重要特性来求解。
假设我们有已分类的文档,
1
2
3
4
| a = "life is short,i like python"
b = "life is too long,i dislike python"
c = "yes,i like python"
label=[1,0,1]
|
词袋法的特征值计算
若使用词袋法,且以训练集中的文本为词汇表,即将训练集中的文本中出现的单词 (不重复) 都统计出来作为词典,那么记单词的数目为 n,这代表了文本的 n 个维度。以上三个文本在这 8 个特征维度上的表示为:
| life | is | i | short | long | like | dislike | too | python | yes |
|---|
| a' | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| b' | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 |
| c' | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
上面 a’,b’ 就是两个文档的词向量的表现形式,对于贝叶斯公式,从 label 中我们可以得出两个类别的概率为:
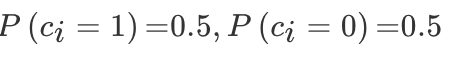
对于一个给定的文档类别,每个单词特征向量的概率是多少呢?
提供一种 TF 计算方法,为类别 yk 每个单词出现的次数 Ni,除以文档类别 yk 中所有单词出现次数的总数 N:
Pi=Ni/N
首先求出现总数,对于 1 类别文档,在 a’ 中,就可得出总数为 1+1+1+1+1+1=6,c’ 中,总共 1+1+1+1=4,故在 1 类别文档中总共有 10 次。
每个单词出现总数,假设是两个列表,a’+c’ 就能得出每个单词出现次数,比如 P(w=python)=2/10=0.20000000,同样可以得到其它的单词概率。最终结果如下:
1
2
3
4
| # 类别1文档中的词向量概率
p1 = [0.10000000,0.10000000,0.20000000,0.10000000,0,0.20000000,0,0,0.20000000,0.10000000]
# 类别0文档中的词向量概率
p0 = [0.16666667,0.16666667,0.16666667,0,0.16666667,0,0.16666667,0.16666667,0.16666667,0]
|
拉普拉斯平滑系数
为了避免训练集样本对一些特征的缺失,即某一些特征出现的次数为 0,在计算 P(X1,X2,X3,…,Xn∣Yi) 的时候,各个概率相乘最终结果为零,这样就会影响结果。我们需要对这个概率计算公式做一个平滑处理:
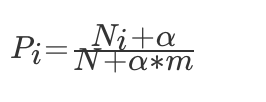
其中 m 为特征词向量的个数,α为平滑系数,当α=1,称为拉普拉斯平滑。
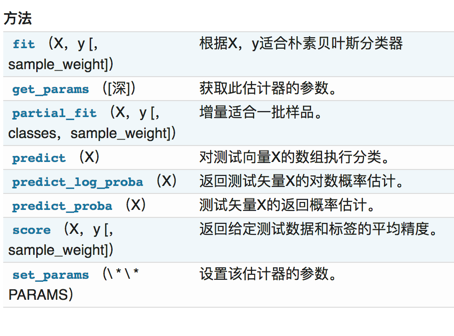
# sklearn.naive_bayes.MultinomialNB
1
2
3
4
| class sklearn.naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)
"""
:param alpha:float,optional(default = 1.0)加法(拉普拉斯/ Lidstone)平滑参数(0为无平滑)
"""
|
# 互联网新闻分类
读取 20 类新闻文本的数据细节
1
2
3
4
5
| from sklearn.datasets import fetch_20newsgroups
news = fetch_20newsgroups(subset='all')
print news.data[0]
|
上述代码得出该数据共有 18846 条新闻,但是这些文本数据既没有被设定特征,也没有数字化的亮度。因此,在交给朴素贝叶斯分类器学习之前,要对数据做进一步的处理。
20 类新闻文本数据分割
1
2
3
| from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(news.data,news.target,test_size=0.25,random_state=42)
|
文本转换为特征向量进行 TF 特征抽取
1
2
3
4
5
6
7
| from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer()
# 训练数据输入,并转换为特征向量
X_train = vec.fit_transform(X_train)
# 测试数据转换
X_test = vec.transform(X_test)
|
朴素贝叶斯分类器对文本数据进行类别预测
1
2
3
4
5
6
7
8
9
10
| from sklearn.naive_bayes import MultinomialNB
# 使用平滑处理初始化的朴素贝叶斯模型
mnb = MultinomialNB(alpha=1.0)
# 利用训练数据对模型参数进行估计
mnb.fit(X_train,y_train)
# 对测试验本进行类别预测。结果存储在变量y_predict中
y_predict = mnb.predict(X_test)
|
性能测试
朴素贝叶斯模型被广泛应用于海量互联网文本分类任务。由于其较强的特征条件独立假设,使得模型预测所需要估计的参数规模从幂指数量级想线性量级减少,极大的节约了内存消耗和计算时间。到那时,也正是受这种强假设的限制,模型训练时无法将各个特征之间的联系考量在内,使得该模型在其他数据特征关联性较强的分类任务上的性能表现不佳。
# 3.4 分类算法之逻辑回归
逻辑回归(Logistic Regression),简称 LR。它的特点是能够是我们的特征输入集合转化为 0 和 1 这两类的概率。一般来说,回归不用在分类问题上,因为回归是连续型模型,而且受噪声影响比较大。如果非要应用进入,可以使用逻辑回归。了解过线性回归之后再来看逻辑回归可以更好的理解。
优点:计算代价不高,易于理解和实现
缺点:容易欠拟合,分类精度不高
适用数据:数值型和标称型
# 逻辑回归
对于回归问题后面会介绍,Logistic 回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数 g(z) 将最为假设函数来预测。g(z) 可以将连续值映射到 0 和 1 上。Logistic 回归用来分类 0/1 问题,也就是预测结果属于 0 或者 1 的二值分类问题
映射函数为:
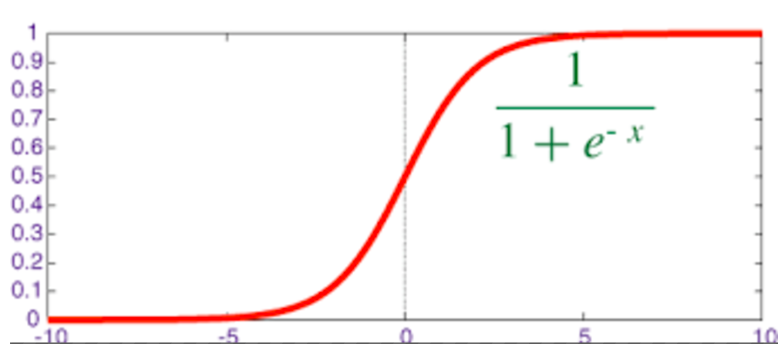
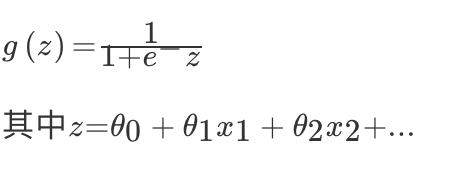 映射出来的效果如下如:
映射出来的效果如下如:
# sklearn.linear_model.LogisticRegression
逻辑回归类
1
2
3
4
5
6
7
8
| class sklearn.linear_model.LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='liblinear', max_iter=100, multi_class='ovr', verbose=0, warm_start=False, n_jobs=1)
"""
:param C: float,默认值:1.0
:param penalty: 特征选择的方式
:param tol: 公差停止标准
"""
|
1
2
3
4
5
6
7
8
9
10
11
| from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
from sklearn.linear_model import LogisticRegression
LR = LogisticRegression(C=1.0, penalty='l1', tol=0.01)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
LR.fit(X_train,y_train)
LR.predict(X_test)
LR.score(X_test,y_test)
0.96464646464646464
# c=100.0
0.96801346801346799
|
# 属性
coef_
决策功能的特征系数
Cs_
数组 C,即用于交叉验证的正则化参数值的倒数
# 特点分析
线性分类器可以说是最为基本和常用的机器学习模型。尽管其受限于数据特征与分类目标之间的线性假设,我们仍然可以在科学研究与工程实践中把线性分类器的表现性能作为基准。
# 3.5 逻辑回归算法案例分析
# 良/恶性乳腺癌肿瘤预测
原始数据的下载地址为:https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/
数据预处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import pandas as pd
import numpy as np
# 根据官方数据构建类别
column_names = ['Sample code number','Clump Thickness ','Uniformity of Cell Size','Uniformity of Cell Shape','Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli','Mitoses','Class'],
data = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/',names = column_names)
# 将?替换成标准缺失值表示
data = data.replace(to_replace='?',value = np.nan)
# 丢弃带有缺失值的数据(只要一个维度有缺失)
data = data.dropna(how='any')
data.shape
|
处理的缺失值后的样本共有 683 条,特征包括细胞厚度、细胞大小、形状等九个维度
准备训练测试数据
1
2
3
4
5
6
7
8
| from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(data[column_names[1:10]],data[column_names[10]],test_size=0.25,random_state=42)
# 查看训练和测试样本的数量和类别分布
y_train.value_counts()
y_test.value_counts()
|
使用逻辑回归进行良/恶性肿瘤预测任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# 标准化数据,保证每个维度的特征数据方差为1,均值为0。使得预测结果不会被某些维度过大的特征值而主导
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
# 初始化 LogisticRegression
lr = LogisticRegression(C=1.0, penalty='l1', tol=0.01)
# 跳用LogisticRegression中的fit函数/模块来训练模型参数
lr.fit(X_train,y_train)
lr_y_predict = lr.predict(X_test)
|
性能分析
1
2
3
4
5
6
| from sklearn.metrics import classification_report
# 利用逻辑斯蒂回归自带的评分函数score获得模型在测试集上的准确定结果
print '精确率为:',lr.score(X_test,y_test)
print classification_report(y_test,lr_y_predict,target_names = ['Benign','Maligant'])
|
# 3.6 分类器性能评估
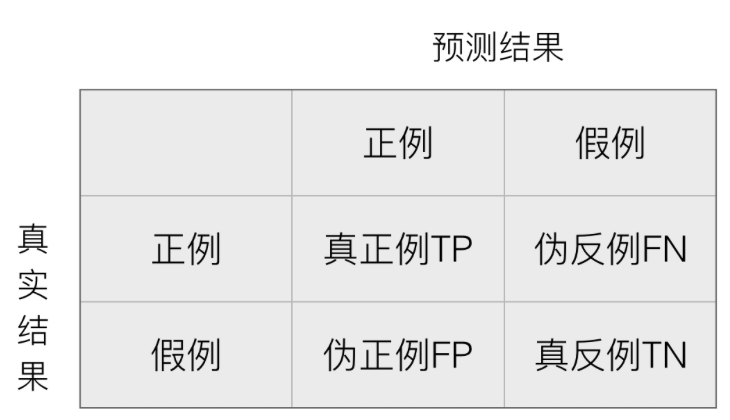
在许多实际问题中,衡量分类器任务的成功程度是通过固定的性能指标来获取。一般最常见使用的是准确率,即预测结果正确的百分比。然而有时候,我们关注的是负样本是否被正确诊断出来。例如,关于肿瘤的的判定,需要更加关心多少恶性肿瘤被正确的诊断出来。也就是说,在二类分类任务下,预测结果 (Predicted Condition) 与正确标记 (True Condition) 之间存在四种不同的组合,构成混淆矩阵。
在二类问题中,如果将一个正例判为正例,那么就可以认为产生了一个真正例(True Positive,TP);如果对一个反例正确的判为反例,则认为产生了一个真反例(True Negative,TN)。相应地,两外两种情况则分别称为伪反例(False Negative,FN,也称)和伪正例(False Positive,TP),四种情况如下图:
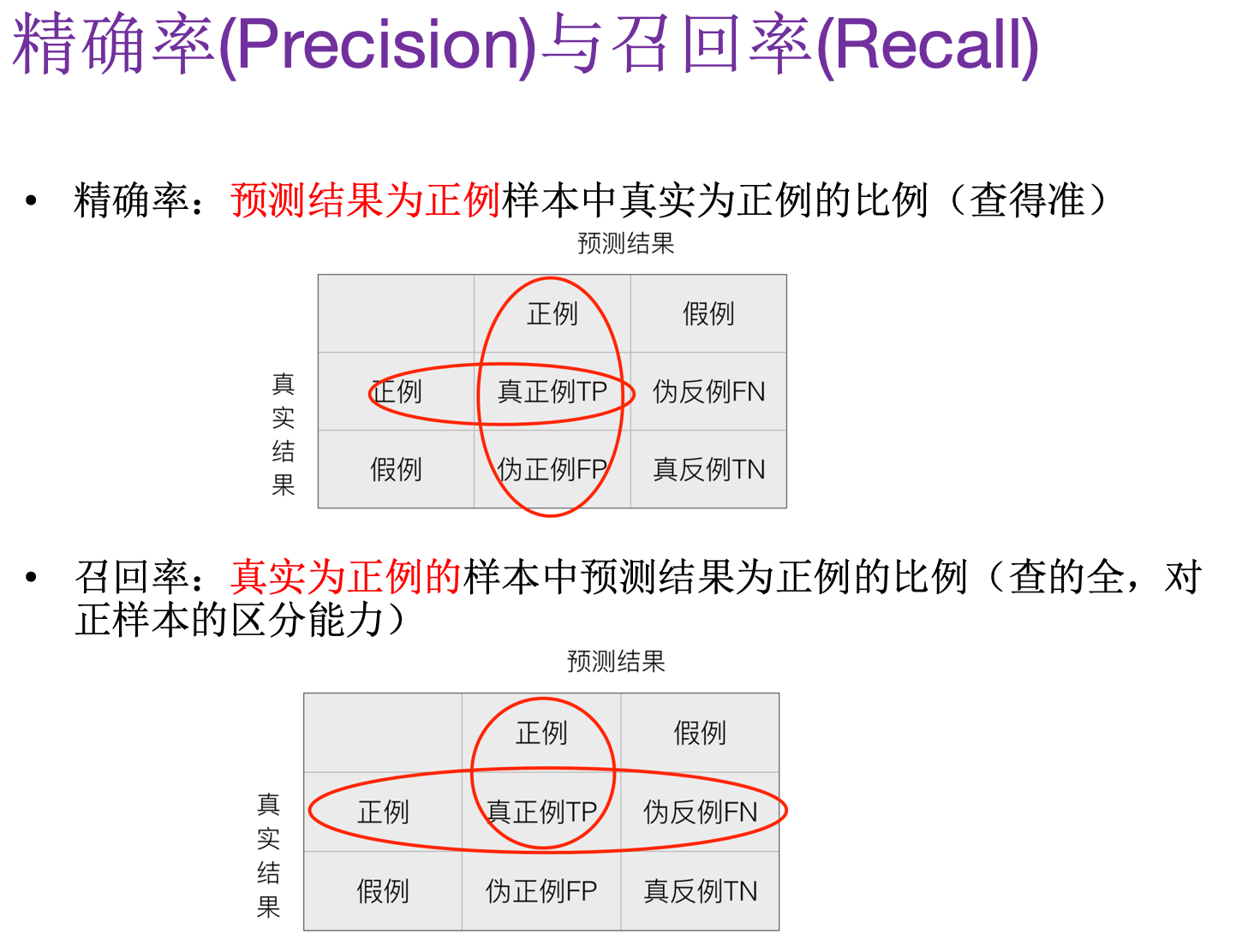
在分类中,当某个类别的重要性高于其他类别时,我们就可以利用上述定义出多个逼错误率更好的新指标。第一个指标就是精确率(Precision),它等于 TP/(TP+FP),给出的是预测为正例的样本中占真实结果总数的比例。第二个指标是召回率(Recall)。它等于 TP/(TP+FN),给出的是预测为正例的真实正例占所有真实正例的比例。
那么除了正确率和精确率这两个指标之外,为了综合考量召回率和精确率,我们计算这两个指标的调和平均数,得到 F1 指标(F1 measure):
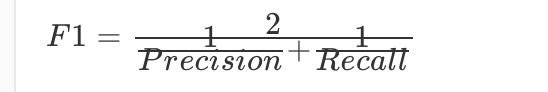
之所以使用调和平均数,是因为它除了具备平均功能外,还会对那些召回率和精确率更加接近的模型给予更高的分数;而这也是我们所希望的,因为那些召回率和精确率差距过大的学习模型,往往没有足够的使用价值。

sklearn.metrics.classification_report

sklearn 中 metrics 中提供了计算四个指标的模块,也就是 classification_report。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| classification_report(y_true, y_pred, labels=None, target_names=None, digits=2)
"""
计算分类指标
:param y_true:真实目标值
:param y_pred:分类器返回的估计值
:param target_names:可选的,计算与目标类别匹配的结果
:param digits:格式化输出浮点值的位数
:return :字符串,三个指标值
"""
|
我们通过一个例子来分析一下指标的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 2]
y_pred = [0, 0, 2, 2, 1]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))
precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
avg / total 0.70 0.60 0.61 5
|
# 3.7 分类算法之决策树
决策树是一种基本的分类方法,当然也可以用于回归。我们一般只讨论用于分类的决策树。决策树模型呈树形结构。在分类问题中,表示基于特征对实例进行分类的过程,它可以认为是 if-then 规则的集合。在决策树的结构中,每一个实例都被一条路径或者一条规则所覆盖。通常决策树学习包括三个步骤:特征选择、决策树的生成和决策树的修剪
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理逻辑回归等不能解决的非线性特征数据
缺点:可能产生过度匹配问题
适用数据类型:数值型和标称型

# 特征选择
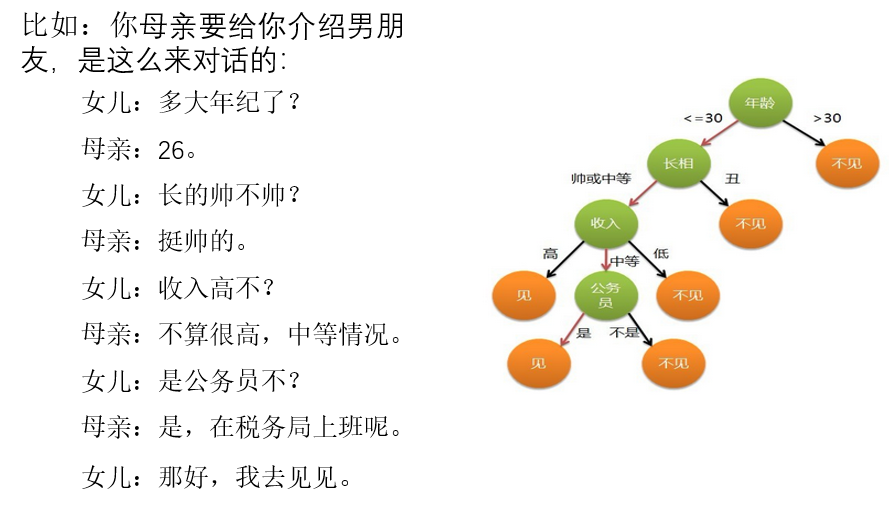
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率,如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的京都影响不大。通常特征选择的准则是信息增益,这是个数学概念。通过一个例子来了解特征选择的过程。
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
我们希望通过所给的训练数据学习一个贷款申请的决策树,用以对文莱的贷款申请进行分类,即当新的客户提出贷款申请是,根据申请人的特征利用决策树决定是否批准贷款申请。特征选择其实是决定用那个特征来划分特征空间。下图中分别是按照年龄,还有是否有工作来划分得到不同的子节点
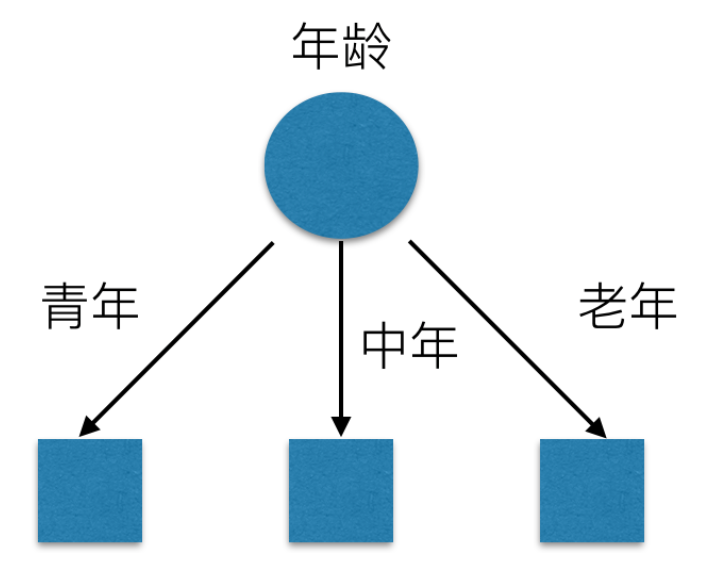
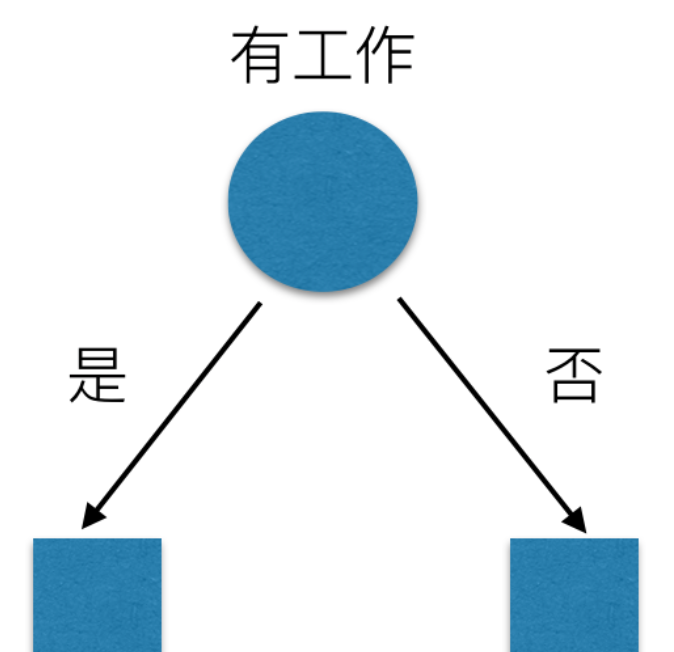
问题是究竟选择哪个特征更好些呢?那么直观上,如果一个特征具有更好的分类能力,是的各个自己在当前的条件下有最好的分类,那么就更应该选择这个特征。信息增益就能很好的表示这一直观的准则。这样得到的一棵决策树只用了两个特征就进行了判断:
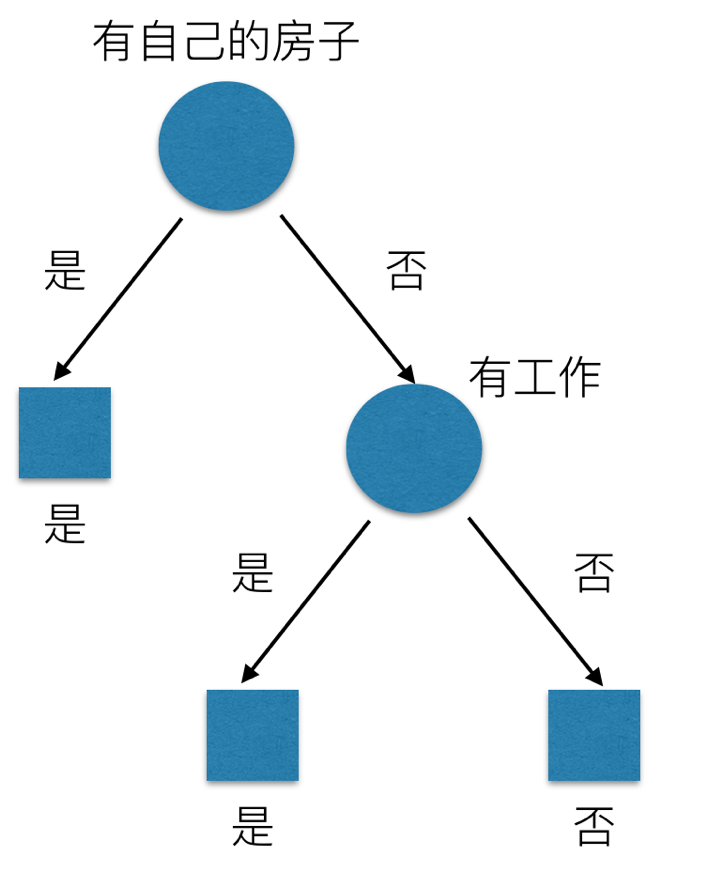
通过信息增益生成的决策树结构,更加明显、快速的划分类别。下面介绍 scikit-learn 中 API 的使用
# 信息的度量和作用
我们常说信息有用,那么它的作用如何客观、定量地体现出来呢?信息用途的背后是否有理论基础呢?这个问题一直没有很好的回答,直到 1948 年,香农在他的论文“通信的数学原理”中提到了“信息熵”的概念,才解决了信息的度量问题,并量化出信息的作用。
一条信息的信息量与其不确定性有着直接的关系,比如我们要搞清一件非常不确定的事,就需要大量的信息。相反如果对某件事了解较多,则不需要太多的信息就能把它搞清楚 。所以从这个角度看,可以认为,信息量就等于不确定的多少。那么如何量化信息量的度量呢?2022 年举行世界杯,大家很关系谁是冠军。假如我错过了看比赛,赛后我问朋友 ,“谁是冠军”?他不愿意直接告诉我,让我每猜一次给他一块钱,他告诉我是否猜对了,那么我需要掏多少钱才能知道谁是冠军?我可以把球编上号,从 1 到 32,然后提问:冠 军在 1-16 号吗?依次询问,只需要五次,就可以知道结果。所以谁是世界杯冠军这条消息只值五块钱。当然香农不是用钱,而是用“比特”这个概念来度量信息量。一个比特是 一位二进制数,在计算机中一个字节是 8 比特。
那么如果说有一天有 64 支球队进行决赛阶段的比赛,那么“谁是世界杯冠军”的信息量就是 6 比特,因为要多猜一次,有的同学就会发现,信息量的比特数和所有可能情况的对数函数 log 有关,(log32=5,log64=6)
另外一方面你也会发现实际上我们不需要猜五次就能才出冠军,因为像西班牙、巴西、德国、意大利这样的球队夺得冠军的可能性比南非、尼日利亚等球队大得多,因此第一次猜测时不需要把 32 支球队等分成两个组,而可以把少数几支最有可能的球队分成一组,把其他球队分成一组。然后才冠军球队是否在那几支热门队中。这样,也许三次就猜出结果。因此,当每支球队夺冠的可能性不等时,“谁是世界杯冠军”的信息量比 5 比特少。香农指出,它的准确信息量应该是:
H = -(p1logp1 + p2logp2 + … + p32log32)
其中,p1…p32 为这三支球队夺冠的概率。H 的专业术语称之为信息熵,单位为比特,当这 32 支球队夺冠的几率相同时,对应的信息熵等于 5 比特,这个可以通过计算得出。有一个特性就是,5 比特是公式的最大值。那么信息熵(经验熵)的具体定义可以为如下:
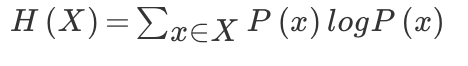
# 信息增益
自古以来,信息和消除不确定性是相联系的。所以决策树的过程其实是在寻找某一个特征对整个分类结果的不确定减少的过程。那么这样就有一个概念叫做信息增益(information gain)。
那么信息增益表示得知特征 X 的信息而是的类 Y 的信息的不确定性减少的程度,所以我们对于选择特征进行分类的时候,当然选择信息增益较大的特征,这样具有较强的分类能力。特征 A 对训练数据集 D 的信息增益 g(D,A),定义为集合 D 的经验熵 H(D) 与特征 A 给定条件下 D 的经验条件熵 H(D|A) 之差,即公式为:
g(D,A)=H(D)−H(D∣A)
根据信息增益的准则的特征选择方法是:对于训练数据集 D,计算其每个特征的信息增益,并比较它们的阿笑,选择信息增益最大的特征
# 信息增益的计算

既然我们有了这两个公式,我们可以根据前面的是否通过贷款申请的例子来通过计算得出我们的决策特征顺序。那么我们首先计算总的经验熵为:
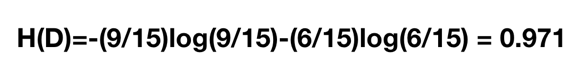
然后我们让 A1,A2,A3,A4A1,A2,A3,A4 分别表示年龄、有工作、有自己的房子和信贷情况 4 个特征,则计算出年龄的信息增益为:

同理其他的也可以计算出来,g(D,A2)=0.324,g(D,A3)=0.420,g(D,A4)=0.363,相比较来说其中特征 A3(有自己的房子)的信息增益最大,所以我们选择特征 A3 为最有特征
# sklearn.tree.DecisionTreeClassifier
sklearn.tree.DecisionTreeClassifier 是一个能对数据集进行多分类的类
1
2
3
4
5
6
| class sklearn.tree.DecisionTreeClassifier(criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_split=1e-07, class_weight=None, presort=False)
"""
:param max_depth:int或None,可选(默认=无)树的最大深度。如果没有,那么节点将被扩展,直到所有的叶子都是纯类,或者直到所有的叶子都包含少于min_samples_split样本
:param random_state:random_state是随机数生成器使用的种子
"""
|
首先我们导入类,以及数据集,还有将数据分成训练数据集和测试数据集两部分
1
2
3
4
5
6
7
8
9
| from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
estimator = DecisionTreeClassifier(max_leaf_nodes=3, random_state=0)
estimator.fit(X_train, y_train)
|
# Method
apply 返回每个样本被预测的叶子的索引
1
2
3
4
5
6
7
8
9
10
11
| estimator.apply(X)
array([ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
5, 5, 15, 5, 5, 5, 5, 5, 5, 10, 5, 5, 5, 5, 5, 10, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 16, 16,
16, 16, 16, 16, 6, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16,
8, 16, 16, 16, 16, 16, 16, 14, 16, 16, 11, 16, 16, 16, 8, 8, 16,
16, 16, 14, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16])
|
decision_path 返回树中的决策路径
1
| dp = estimator.decision_path(X_test)
|
**fit_transform(X,y=None,fit_params) 输入数据,然后转换
predict(X) 预测输入数据的类型,完整代码
1
2
3
4
5
6
7
8
| estimator.predict(X_test)
array([2, 1, 0, 2, 0, 2, 0, 1, 1, 1, 2, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0,
0, 1, 0, 0, 1, 1, 0, 2, 1, 0, 1, 2, 1, 0, 2])
print y_test
array([2, 1, 0, 2, 0, 2, 0, 1, 1, 1, 2, 1, 1, 1, 1, 0, 1, 1, 0, 0, 2, 1, 0,
0, 2, 0, 0, 1, 1, 0, 2, 1, 0, 2, 2, 1, 0, 1])
|
score(X,y,sample_weight=None) 返回给定测试数据的准确精度
1
2
3
| estimator.score(X_test,y_test)
0.89473684210526316
|
# 决策树本地保存
sklearn.tree.export_graphviz() 该函数能够导出 DOT 格式
1
2
3
4
5
6
| from sklearn.datasets import load_iris
from sklearn import tree
clf = tree.DecisionTreeClassifier()
iris = load_iris()
clf = clf.fit(iris.data, iris.target)
tree.export_graphviz(clf,out_file='tree.dot')
|
那么有了 tree.dot 文件之后,我们可以通过命令转换为 png 或者 pdf 格式,首先得安装 graphviz
1
2
| ubuntu:sudo apt-get install graphviz
Mac:brew install graphviz
|
然后我们运行这个命令
1
2
| $ dot -Tps tree.dot -o tree.ps
$ dot -Tpng tree.dot -o tree.png
|
或者,如果我们安装了 Python 模块 pydotplus,我们可以直接在 Python 中生成 PDF 文件,通过 pip install pydotplus,然后运行
1
2
3
4
| import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")
|
查看决策树结构图片,这个结果是经过决策树学习的三个步骤之后形成的。当作了解
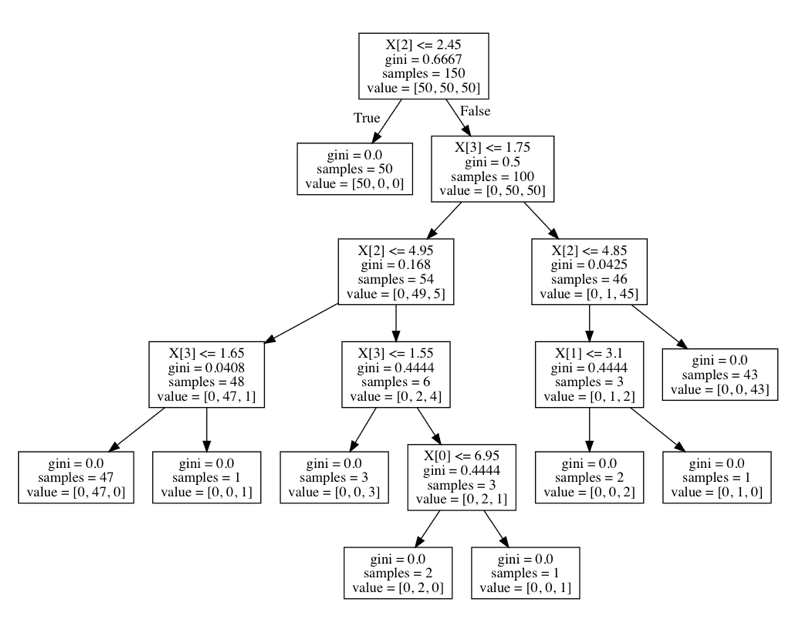
扩展:所有各种决策树算法是什么,它们之间有什么不同?哪一个在 scikit-learn 中实现?
ID3 — 信息增益 最大的准则
C4.5 — 信息增益比 最大的准则
CART 回归树: 平方误差 最小 分类树: 基尼系数 最小的准则 在 sklearn 中可以选择划分的原则
# 决策树优缺点分析
决策树的一些优点是:
- 简单的理解和解释。树木可视化。
- 需要很少的数据准备。其他技术通常需要数据归一化,需要创建虚拟变量,并删除空值。但请注意,此模块不支持缺少值。
- 使用树的成本(即,预测数据)在用于训练树的数据点的数量上是对数的。
决策树的缺点包括:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树。这被称为过拟合。修剪(目前不支持)的机制,设置叶节点所需的最小采样数或设置树的最大深度是避免此问题的必要条件。
- 决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成。通过使用合奏中的决策树来减轻这个问题。
# 3.8 集成方法(分类)之随机森林
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。利用相同的训练数搭建多个独立的分类模型,然后通过投票的方式,以少数服从多数的原则作出最终的分类决策。例如, 如果你训练了 5 个树, 其中有 4 个树的结果是 True, 1 个数的结果是 False, 那么最终结果会是 True.
在前面的决策当中我们提到,一个标准的决策树会根据每维特征对预测结果的影响程度进行排序,进而决定不同的特征从上至下构建分裂节点的顺序,如此以来,所有在随机森林中的决策树都会受这一策略影响而构建的完全一致,从而丧失的多样性。所以在随机森林分类器的构建过程中,每一棵决策树都会放弃这一固定的排序算法,转而随机选取特征。
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
定义:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
优点:
- 在当前所有算法中,具有极好的准确率
- 能够有效地运行在大数据集上
- 能够处理具有高维特征的输入样本,而且不需要降维
- 能够评估各个特征在分类问题上的重要性
- 对于缺省值问题也能够获得很好得结果


# 学习算法
根据下列算法而建造每棵树:
- 用 N 来表示训练用例(样本)的个数,M 表示特征数目。
- 输入特征数目 m,用于确定决策树上一个节点的决策结果;其中 m 应远小于 M。
- 从 N 个训练用例(样本)中以有放回抽样的方式,取样 N 次,形成一个训练集(即 bootstrap 取样),并用未抽到的用例(样本)作预测,评估其误差。
- 对于每一个节点,随机选择 m 个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这 m 个特征,计算其最佳的分裂方式。
# sklearn.ensemble,集成方法模块
sklearn.ensemble 提供了准确性更加好的集成方法,里面包含了主要的 RandomForestClassifier(随机森林) 方法。
1
2
3
4
5
6
7
8
9
10
11
| class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, oob_score=False, n_jobs=1, random_state=None)
"""
:param n_estimators:integer,optional(default = 10) 森林里的树木数量。
:param criteria:string,可选(default =“gini”)分割特征的测量方法
:param max_depth:integer或None,可选(默认=无)树的最大深度
:param bootstrap:boolean,optional(default = True)是否在构建树时使用自举样本。
"""
|
# 属性
- classes_:shape = [n_classes] 的数组或这样的数组的列表,类标签(单输出问题)或类标签数组列表(多输出问题)。
- featureimportances:array = [n_features] 的数组, 特征重要性(越高,功能越重要)。
# 方法
- fit(X,y [,sample_weight]) 从训练集(X,Y)构建一棵树林。
- predict(X) 预测 X 的类
- score(X,y [,sample_weight]) 返回给定测试数据和标签的平均精度。
- decision_path(X) 返回森林中的决策路径
# 泰坦尼克号乘客数据案例

这里我们通过决策树和随机森林对这个数据进行一个分类,判断乘客的生还。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| import pandas as pd
import sklearn
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
#选取一些特征作为我们划分的依据
x = titanicspan>&
y = titanic['survived']
# 填充缺失值
x['age'].fillna(x['age'].mean(), inplace=True)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
dt = DictVectorizer(sparse=False)
print(x_train.to_dict(orient="record"))
# 按行,样本名字为键,列名也为键,[{"1":1,"2":2,"3":3}]
x_train = dt.fit_transform(x_train.to_dict(orient="record"))
x_test = dt.fit_transform(x_test.to_dict(orient="record"))
# 使用决策树
dtc = DecisionTreeClassifier()
dtc.fit(x_train, y_train)
dt_predict = dtc.predict(x_test)
print(dtc.score(x_test, y_test))
print(classification_report(y_test, dt_predict, target_names=["died", "survived"]))
# 使用随机森林
rfc = RandomForestClassifier()
rfc.fit(x_train, y_train)
rfc_y_predict = rfc.predict(x_test)
print(rfc.score(x_test, y_test))
print(classification_report(y_test, rfc_y_predict, target_names=["died", "survived"]))
|
# 总结
# 4. 回归算法
回归是统计学中最有力的工具之一。机器学习监督学习算法分为分类算法和回归算法两种,其实就是根据类别标签分布类型为离散型、连续性而定义的。回归算法用于连续型分布预测,针对的是数值型的样本,使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样可以预测连续型数据而不仅仅是离散的类别标签。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。那么什么是线性关系和非线性关系?
比如说在房价上,房子的面积和房子的价格有着明显的关系。那么 X=房间大小,Y=房价,那么在坐标系中可以看到这些点:
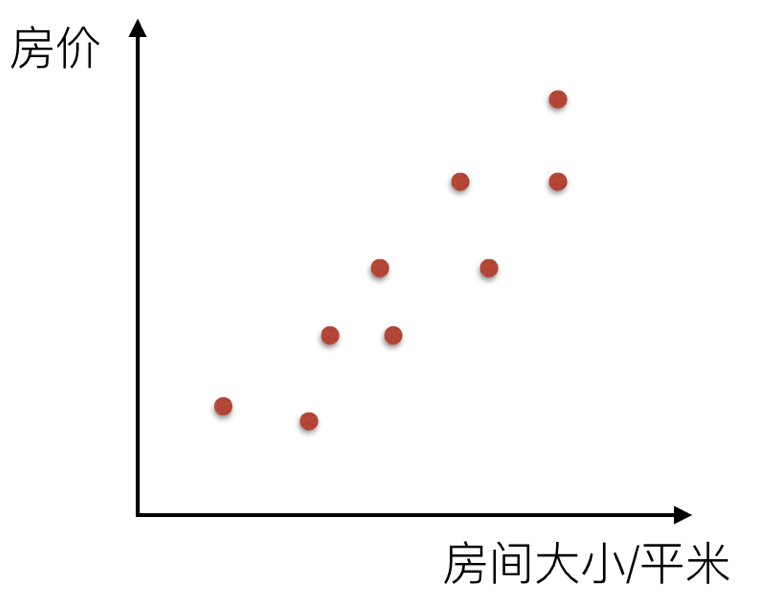
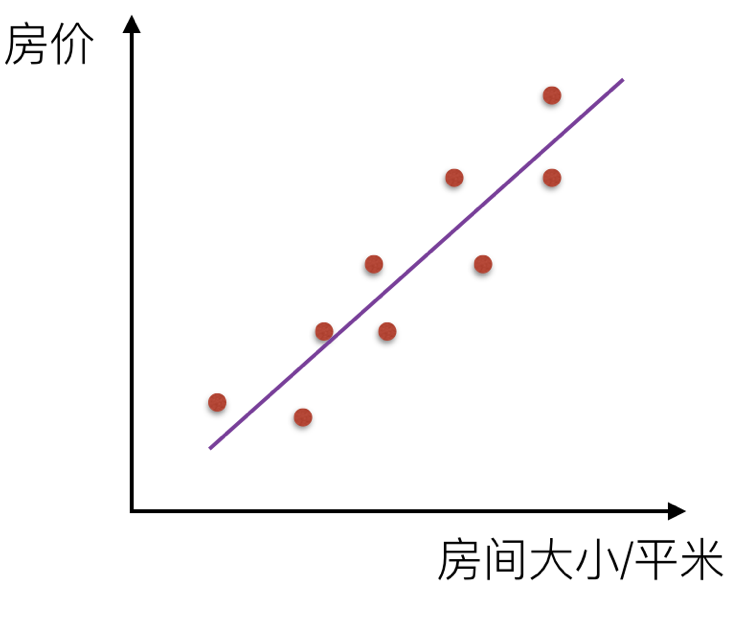
那么通过一条直线把这个关系描述出来,叫线性关系。
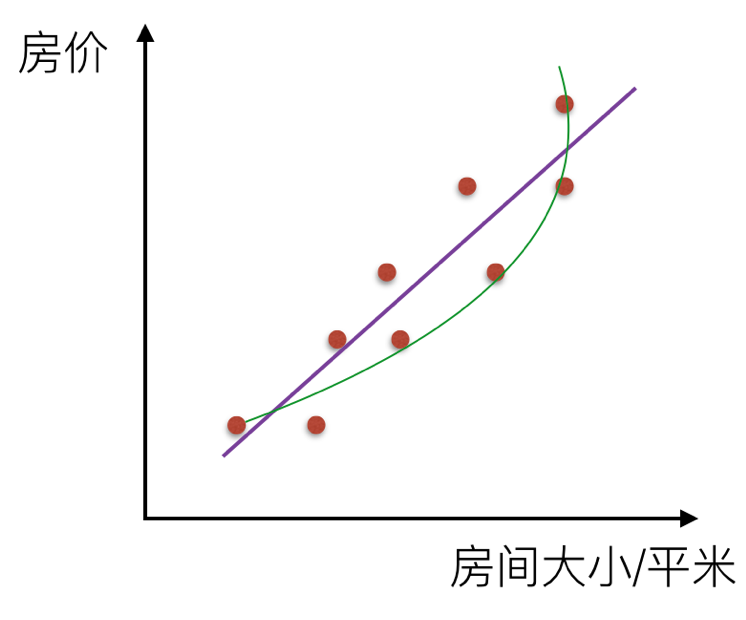
如果是一条曲线,那么叫非线性关系
那么回归的目的就是建立一个回归方程(函数)用来预测目标值,回归的求解就是求这个回归方程的回归系数。
# 4.1 回归算法之线性回归
线性回归的定义是:目标值预期是输入变量的线性组合。线性模型形式简单、易于建模,但却蕴含着机器学习中一些重要的基本思想。线性回归,是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。
优点:结果易于理解,计算不复杂
缺点:对非线性的数据拟合不好
适用数据类型:数值型和标称型
对于单变量线性回归,例如:前面房价例子中房子的大小预测房子的价格。f(x) = w1*x+w0,这样通过主要参数 w1 就可以得出预测的值。
通用公式为:
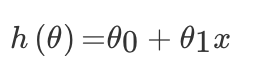
那么对于多变量回归,例如:瓜的好坏程度 f(x) = w0+0.2* 色泽 +0.5* 根蒂 +0.3* 敲声,得出的值来判断一个瓜的好与不好的程度。
通用公式为:
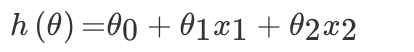
线性模型中的向量 W 值,客观的表达了各属性在预测中的重要性,因此线性模型有很好的解释性。对于这种“多特征预测”也就是(多元线性回归),那么线性回归就是在这个基础上得到这些 W 的值,然后以这些值来建立模型,预测测试数据。简单的来说就是学得一个线性模型以尽可能准确的预测实值输出标记。
那么如果对于多变量线性回归来说我们可以通过向量的方式来表示 W 值与特征 X 值之间的关系:
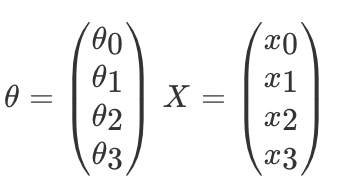
两向量相乘,结果为一个整数是估计值,其中所有特征集合的第一个特征值 x0=1,那么我们可以通过通用的向量公式来表示线性模型:
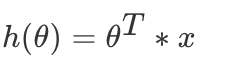
一个列向量的转置与特征的乘积,得出我们预测的结果,但是显然我们这个模型得到的结果可定会有误差,如下图所示:
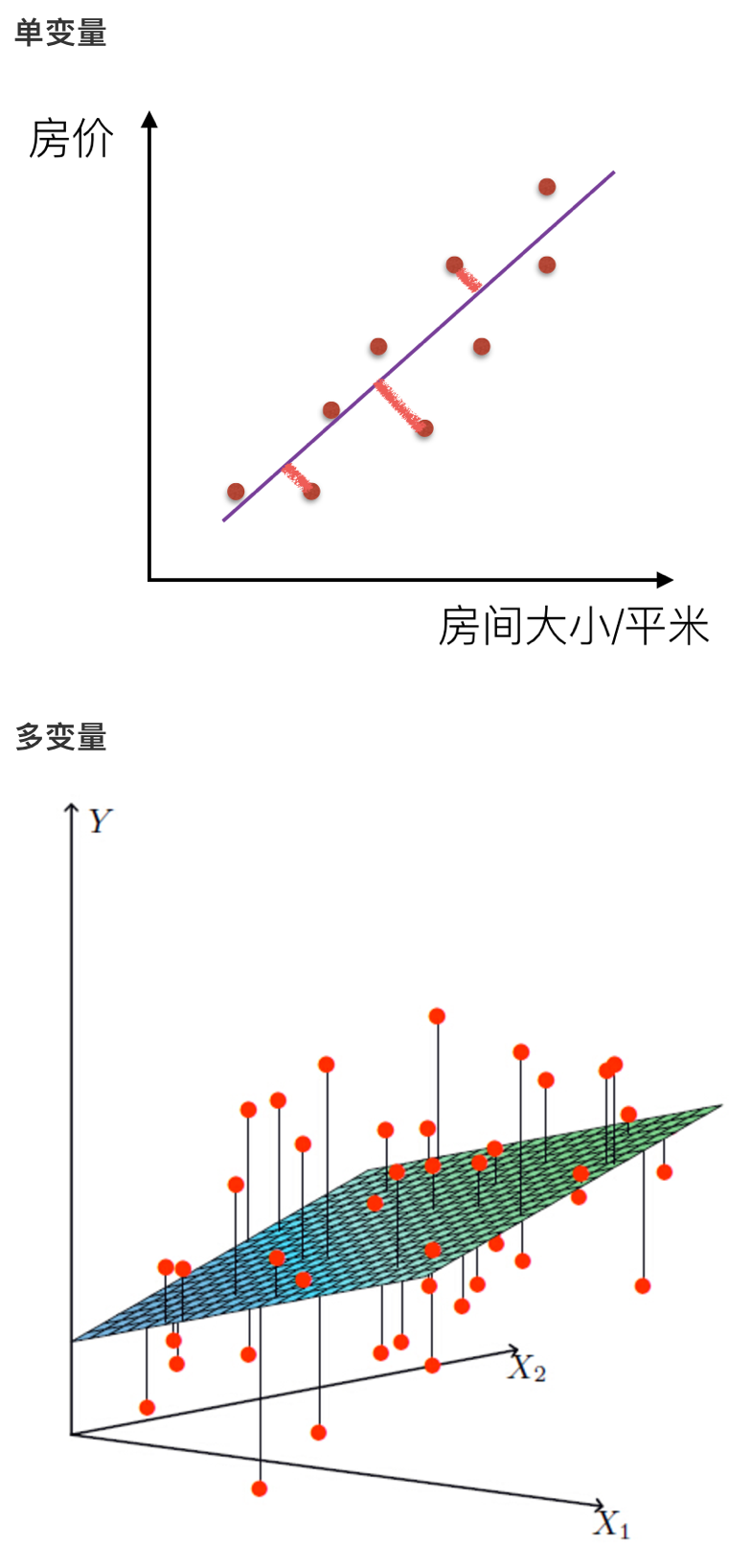
# 损失函数
损失函数是一个贯穿整个机器学习重要的一个概念,大部分机器学习算法都会有误差,我们得通过显性的公式来描述这个误差,并且将这个误差优化到最小值。
对于线性回归模型,将模型与数据点之间的距离差之和做为衡量匹配好坏的标准,误差越小,匹配程度越大。我们要找的模型就是需要将 f(x) 和我们的真实值之间最相似的状态。于是我们就有了误差公式,模型与数据差的平方和最小:
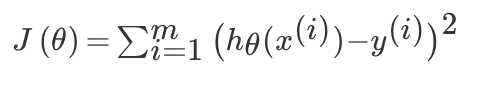
上面公式定义了所有的误差和,那么现在需要使这个值最小?那么有两种方法,一种使用梯度下降算法,另一种使正规方程解法(只适用于简单的线性回归)。
# 梯度下降算法
上面误差公式是一个通式,我们取两个单个变量来求最小值,误差和可以表示为:
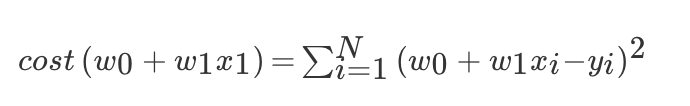
可以通过调整不同的 w1 和 w0 的值,就能使误差不断变化,而当你找到这个公式的最小值时,你就能得到最好的 w1,w0 而这对 (w1,w0) 就是能最好描述你数据关系的模型参数。
怎么找 cost(w0+w1x1) 的最小? cost(w0+w1x1) 的图像其实像一个山谷一样,有一个最低点。找这个最低点的办法就是,先随便找一个点 (w1=5, w0=4), 然后 沿着这个碗下降的方向找,最后就能找到山谷的最低点。
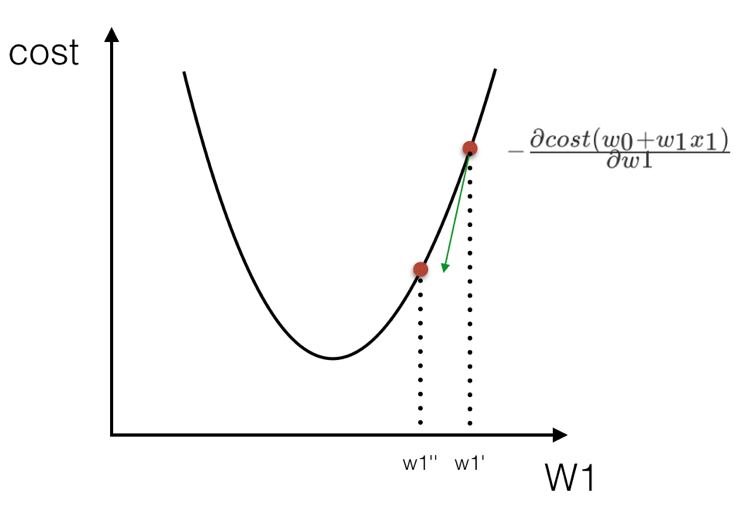
所以得出
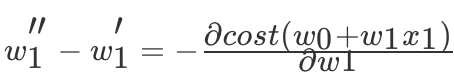 ,那么这个过程是按照某一点在 w1 上的偏导数下降寻找最低点。当然在进行移动的时候也需要考虑,每次移动的速度,也就是αα的值,这个值也叫做(学习率),如下式:
,那么这个过程是按照某一点在 w1 上的偏导数下降寻找最低点。当然在进行移动的时候也需要考虑,每次移动的速度,也就是αα的值,这个值也叫做(学习率),如下式:
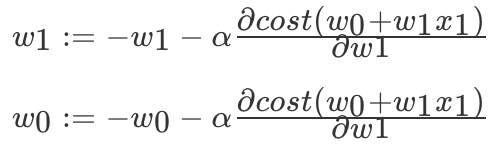
这样就能求出 w0,w1 的值,当然你这个过程是不断的进行迭代求出来,通过交叉验证方法即可。
# LinearRegression
# sklearn.linear_model.LinearRegression
1
2
3
4
5
6
7
8
| class LinearRegression(fit_intercept = True,normalize = False,copy_X = True,n_jobs = 1)
"""
:param normalize:如果设置为True时,数据进行标准化。请在使用normalize = False的估计器调时用fit之前使用preprocessing.StandardScaler
:param copy_X:boolean,可选,默认为True,如果为True,则X将被复制
:param n_jobs:int,可选,默认1。用于计算的CPU核数
"""
|
实例代码:
1
2
| from sklearn.linear_model import LinearRegression
reg = LinearRegression()
|
# 方法
fit(X,y,sample_weight = None)
使用 X 作为训练数据拟合模型,y 作为 X 的类别值。X,y 为数组或者矩阵
1
| reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
|
predict(X)
预测提供的数据对应的结果
1
2
3
| reg.predict(span>)
array([ 3.])
|
# 属性
coef_
表示回归系数 w=(w1,w2….)
1
2
3
| reg.coef_
array([ 0.5, 0.5])
|
intercept_ 表示 w0
# 加入交叉验证
前面我们已经提到了模型的交叉验证,那么我们这个自己去建立数据集,然后通过线性回归的交叉验证得到模型。由于 sklearn 中另外两种回归岭回归、lasso 回归都本省提供了回归 CV 方法,比如 linear_model.Lasso,交叉验证 linear_model.LassoCV;linear_model.Ridge,交叉验证 linear_model.RidgeCV。所以我们需要通过前面的 cross_validation 提供的方法进行 k- 折交叉验证。
1
2
3
4
5
6
7
8
9
| from sklearn.datasets.samples_generator import make_regression
from sklearn.model_selection import cross_val_score
from sklearn import linear_model
import matplotlib.pyplot as plt
lr = linear_model.LinearRegression()
X, y = make_regression(n_samples=200, n_features=5000, random_state=0)
result = cross_val_score(lr, X, y)
print result
|
# 4.2 线性回归案例分析
# 波士顿房价预测
使用 scikit-learn 中内置的回归模型对“美国波士顿房价”数据进行预测。对于一些比赛数据,可以从 kaggle 官网上获取,网址:https://www.kaggle.com/datasets
1.美国波士顿地区房价数据描述
1
2
3
4
5
| from sklearn.datasets import load_boston
boston = load_boston()
print boston.DESCR
|
2.波士顿地区房价数据分割
1
2
3
4
5
6
| from sklearn.cross_validation import train_test_split
import numpy as np
X = boston.data
y = boston.target
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=33,test_size = 0.25)
|
3.训练与测试数据标准化处理
1
2
3
4
5
6
7
8
| from sklearn.preprocessing import StandardScaler
ss_X = StandardScaler()
ss_y = StandardScaler()
X_train = ss_X.fit_transform(X_train)
X_test = ss_X.transform(X_test)
y_train = ss_X.fit_transform(y_train)
X_train = ss_X.transform(y_test)
|
4.使用最简单的线性回归模型 LinearRegression 和梯度下降估计 SGDRegressor 对房价进行预测
1
2
3
4
5
6
7
8
9
| from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train,y_train)
lr_y_predict = lr.predict(X_test)
from sklearn.linear_model import SGDRegressor
sgdr = SGDRegressor()
sgdr.fit(X_train,y_train)
sgdr_y_predict = sgdr.predict(X_test)
|
5.性能评测
对于不同的类别预测,我们不能苛刻的要求回归预测的数值结果要严格的与真实值相同。一般情况下,我们希望衡量预测值与真实值之间的差距。因此,可以测评函数进行评价。其中最为直观的评价指标均方误差 (Mean Squared Error)MSE,因为这也是线性回归模型所要优化的目标。
MSE 的计算方法如式:
MSE=1m∑i=1m(yi−y¯)2MSE=m1∑i=1m(y**i−y¯)2
使用 MSE 评价机制对两种模型的回归性能作出评价
1
2
3
4
| from sklearn.metrics import mean_squared_error
print '线性回归模型的均方误差为:',mean_squared_error(ss_y.inverse_transform(y_test),ss_y.inverse_tranform(lr_y_predict))
print '梯度下降模型的均方误差为:',mean_squared_error(ss_y.inverse_transform(y_test),ss_y.inverse_tranform(sgdr_y_predict))
|
通过这一比较发现,使用梯度下降估计参数的方法在性能表现上不及使用解析方法的 LinearRegression,但是如果面对训练数据规模十分庞大的任务,随即梯度法不论是在分类还是回归问题上都表现的十分高效,可以在不损失过多性能的前提下,节省大量计算时间。根据 Scikit-learn 光网的建议,如果数据规模超过 10 万,推荐使用随机梯度法估计参数模型。
注意:线性回归器是最为简单、易用的回归模型。正式因为其对特征与回归目标之间的线性假设,从某种程度上说也局限了其应用范围。特别是,现实生活中的许多实例数据的各种特征与回归目标之间,绝大多数不能保证严格的线性关系。尽管如此,在不清楚特征之间关系的前提下,我们仍然可以使用线性回归模型作为大多数数据分析的基线系统。
完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_boston
from sklearn.cross_validation import train_test_split
from sklearn.metrics import mean_squared_error,classification_report
from sklearn.cluster import KMeans
def linearmodel():
"""
线性回归对波士顿数据集处理
:return: None
"""
# 1、加载数据集
ld = load_boston()
x_train,x_test,y_train,y_test = train_test_split(ld.data,ld.target,test_size=0.25)
# 2、标准化处理
# 特征值处理
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
# 目标值进行处理
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
# 3、估计器流程
# LinearRegression
lr = LinearRegression()
lr.fit(x_train,y_train)
# print(lr.coef_)
y_lr_predict = lr.predict(x_test)
y_lr_predict = std_y.inverse_transform(y_lr_predict)
print("Lr预测值:",y_lr_predict)
# SGDRegressor
sgd = SGDRegressor()
sgd.fit(x_train,y_train)
# print(sgd.coef_)
y_sgd_predict = sgd.predict(x_test)
y_sgd_predict = std_y.inverse_transform(y_sgd_predict)
print("SGD预测值:",y_sgd_predict)
# 带有正则化的岭回归
rd = Ridge(alpha=0.01)
rd.fit(x_train,y_train)
y_rd_predict = rd.predict(x_test)
y_rd_predict = std_y.inverse_transform(y_rd_predict)
print(rd.coef_)
# 两种模型评估结果
print("lr的均方误差为:",mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
print("SGD的均方误差为:",mean_squared_error(std_y.inverse_transform(y_test),y_sgd_predict))
print("Ridge的均方误差为:",mean_squared_error(std_y.inverse_transform(y_test),y_rd_predict))
return None
|
# 4.3 欠拟合与过拟合
机器学习中的泛化,泛化即是,模型学习到的概念在它处于学习的过程中时模型没有遇见过的样本时候的表现。在机器学习领域中,当我们讨论一个机器学习模型学习和泛化的好坏时,我们通常使用术语:过拟合和欠拟合。我们知道模型训练和测试的时候有两套数据,训练集和测试集。在对训练数据进行拟合时,需要照顾到每个点,而其中有一些噪点,当某个模型过度的学习训练数据中的细节和噪音,以至于模型在新的数据上表现很差,这样的话模型容易复杂,拟合程度较高,造成过拟合。而相反如果值描绘了一部分数据那么模型复杂度过于简单,欠拟合指的是模型在训练和预测时表现都不好的情况,称为欠拟合。
我们来看一下线性回归中拟合的几种情况图示:
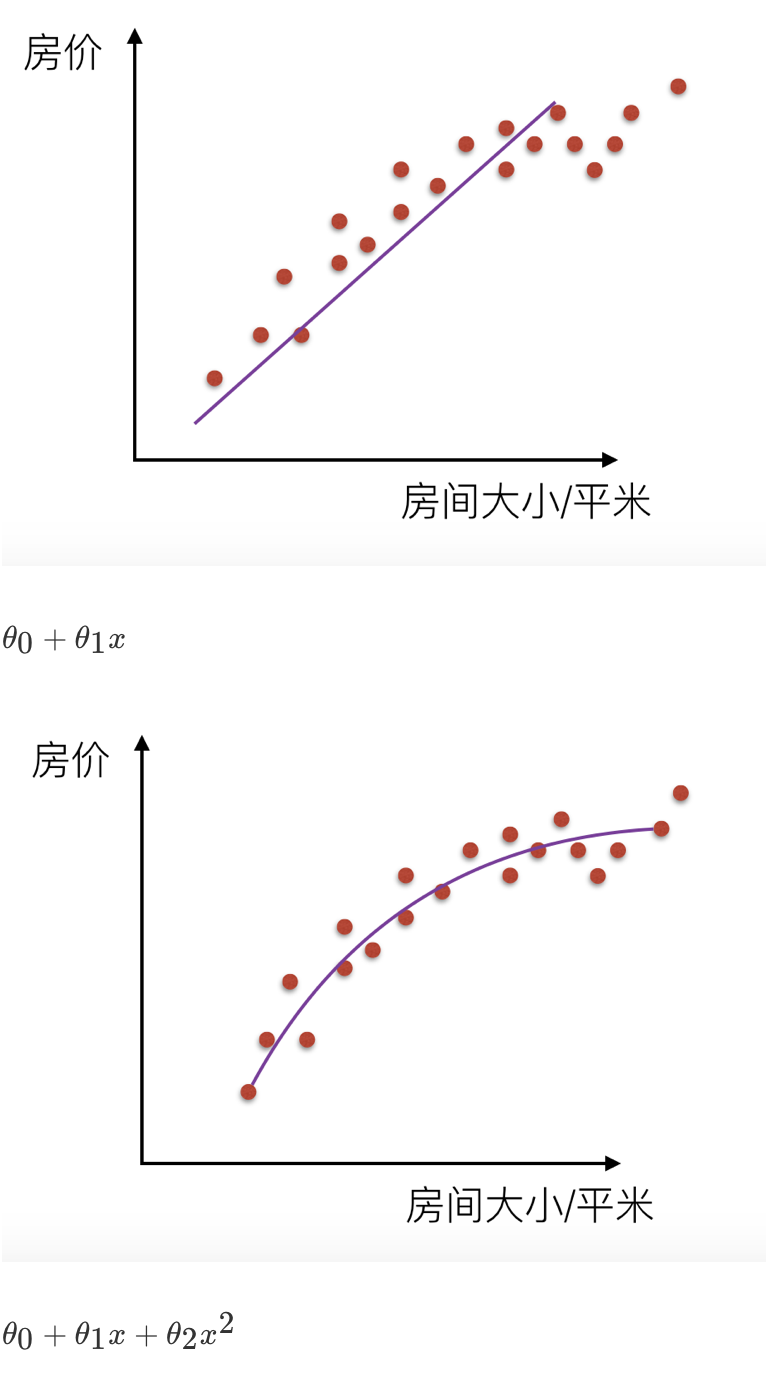
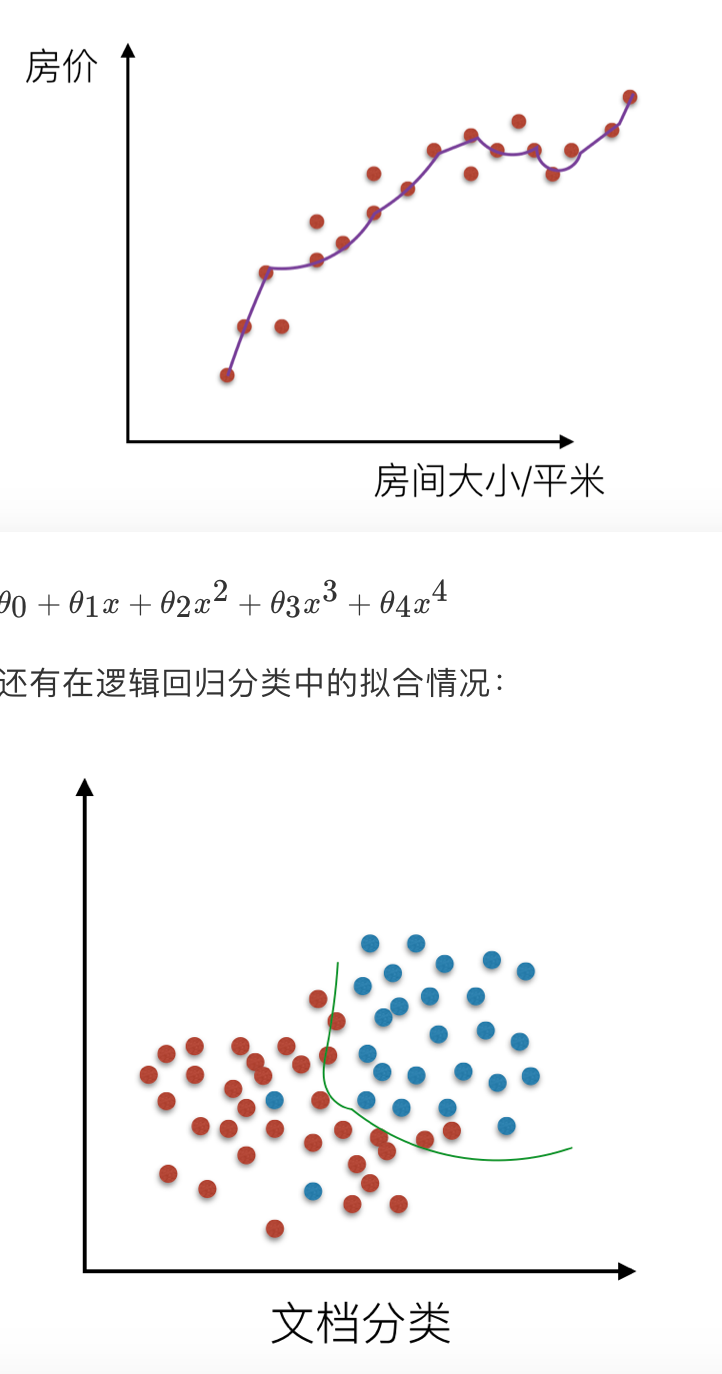
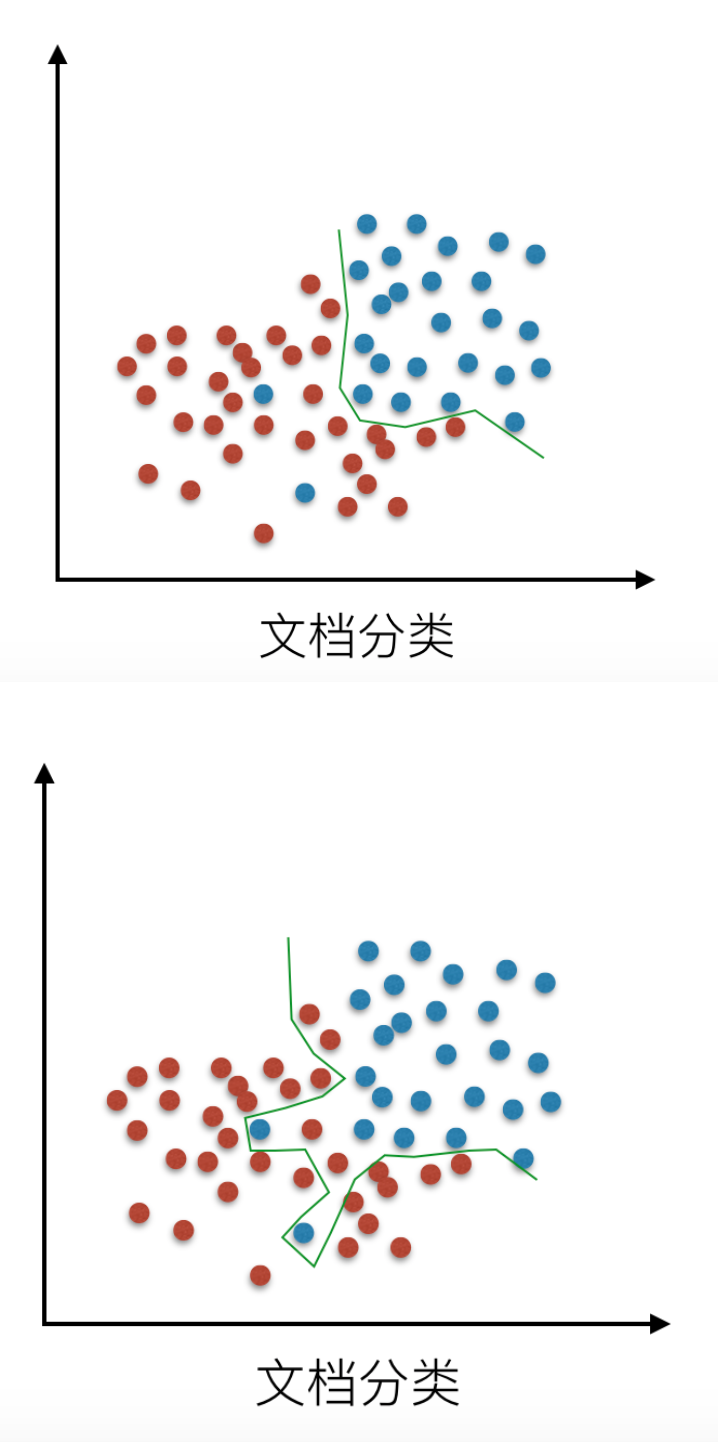
# 解决过拟合的方法
在线性回归中,对于特征集过小的情况,容易造成欠拟合(underfitting),对于特征集过大的情况,容易造成过拟合(overfitting)。针对这两种情况有了更好的解决办法
# 欠拟合
欠拟合指的是模型在训练和预测时表现都不好的情况,欠拟合通常不被讨论,因为给定一个评估模型表现的指标的情况下,欠拟合很容易被发现。矫正方法是继续学习并且试着更换机器学习算法。
# 过拟合
对于过拟合,特征集合数目过多,我们需要做的是尽量不让回归系数数量变多,对拟合(损失函数)加以限制。
(1)当然解决过拟合的问题可以减少特征数,显然这只是权宜之计,因为特征意味着信息,放弃特征也就等同于丢弃信息,要知道,特征的获取往往也是艰苦卓绝的。
(2)引入了 正则化 概念。
直观上来看,如果我们想要解决上面回归中的过拟合问题,我们最好就要消除 x3*x*3 和 x4*x*4 的影响,也就是想让θ3,θ4*θ*3,*θ*4 都等于 0,一个简单的方法就是我们对θ3,θ4*θ*3,*θ*4 进行惩罚,增加一个很大的系数,这样在优化的过程中就会使这两个参数为零。
# 4.4 回归算法之岭回归
具有 L2 正则化的线性最小二乘法。岭回归是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。当数据集中存在共线性的时候,岭回归就会有用。
# sklearn.linear_model.Ridge
1
2
3
4
5
6
7
| class sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True, normalize=False, copy_X=True, max_iter=None, tol=0.001, solver='auto', random_state=None)**
"""
:param alpha:float类型,正规化的程度
"""
from sklearn.linear_model import Ridge
clf = Ridge(alpha=1.0)
clf.fit([[0, 0], [0, 0], [1, 1]], [0, .1, 1]))
|
# 方法
score(X, y, sample_weight=None)
# 属性
coef_
1
2
| clf.coef_
array([ 0.34545455, 0.34545455])
|
intercept_
1
2
| clf.intercept_
0.13636...
|
# 案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
| def linearmodel():
"""
线性回归对波士顿数据集处理
:return: None
"""
# 1、加载数据集
ld = load_boston()
x_train,x_test,y_train,y_test = train_test_split(ld.data,ld.target,test_size=0.25)
# 2、标准化处理
# 特征值处理
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
# 目标值进行处理
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
# 3、估计器流程
# LinearRegression
lr = LinearRegression()
lr.fit(x_train,y_train)
# print(lr.coef_)
y_lr_predict = lr.predict(x_test)
y_lr_predict = std_y.inverse_transform(y_lr_predict)
print("Lr预测值:",y_lr_predict)
# SGDRegressor
sgd = SGDRegressor()
sgd.fit(x_train,y_train)
# print(sgd.coef_)
y_sgd_predict = sgd.predict(x_test)
y_sgd_predict = std_y.inverse_transform(y_sgd_predict)
print("SGD预测值:",y_sgd_predict)
# 带有正则化的岭回归
rd = Ridge(alpha=0.01)
rd.fit(x_train,y_train)
y_rd_predict = rd.predict(x_test)
y_rd_predict = std_y.inverse_transform(y_rd_predict)
print(rd.coef_)
# 两种模型评估结果
print("lr的均方误差为:",mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
print("SGD的均方误差为:",mean_squared_error(std_y.inverse_transform(y_test),y_sgd_predict))
print("Ridge的均方误差为:",mean_squared_error(std_y.inverse_transform(y_test),y_rd_predict))
return None
|
# 5. 非监督学习
从本节开始,将正式进入到无监督学习(Unsupervised Learning)部分。无监督学习,顾名思义,就是不受监督的学习,一种自由的学习方式。该学习方式不需要先验知识进行指导,而是不断地自我认知,自我巩固,最后进行自我归纳,在机器学习中,无监督学习可以被简单理解为不为训练集提供对应的类别标识(label),其与有监督学习的对比如下: 有监督学习(Supervised Learning)下的训练集:
(x(1),y(1)),(x(2),y2)(x(1),y(1)),(x(2),y2)
无监督学习(Unsupervised Learning)下的训练集:
(x(1)),(x(2)),(x(3))(x(1)),(x(2)),(x(3))
在有监督学习中,我们把对样本进行分类的过程称之为分类(Classification),而在无监督学习中,我们将物体被划分到不同集合的过程称之为聚类(Clustering)
##5.1 非监督学习之 k-means
K-means 通常被称为劳埃德算法,这在数据聚类中是最经典的,也是相对容易理解的模型。算法执行的过程分为 4 个阶段。
- 1.首先,随机设 K 个特征空间内的点作为初始的聚类中心。
- 2.然后,对于根据每个数据的特征向量,从 K 个聚类中心中寻找距离最近的一个,并且把该数据标记为这个聚类中心。
- 3.接着,在所有的数据都被标记过聚类中心之后,根据这些数据新分配的类簇,通过取分配给每个先前质心的所有样本的平均值来创建新的质心重,新对 K 个聚类中心做计算。
- 4.最后,计算旧和新质心之间的差异,如果所有的数据点从属的聚类中心与上一次的分配的类簇没有变化,那么迭代就可以停止,否则回到步骤 2 继续循环。
K 均值等于具有小的全对称协方差矩阵的期望最大化算法。
# sklearn.cluster.KMeans
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| class sklearn.cluster.KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto')
"""
:param n_clusters:要形成的聚类数以及生成的质心数
:param init:初始化方法,默认为'k-means ++',以智能方式选择k-均值聚类的初始聚类中心,以加速收敛;random,从初始质心数据中随机选择k个观察值(行
:param n_init:int,默认值:10使用不同质心种子运行k-means算法的时间。最终结果将是n_init连续运行在惯性方面的最佳输出。
:param n_jobs:int用于计算的作业数量。这可以通过并行计算每个运行的n_init。如果-1使用所有CPU。如果给出1,则不使用任何并行计算代码,这对调试很有用。对于-1以下的n_jobs,使用(n_cpus + 1 + n_jobs)。因此,对于n_jobs = -2,所有CPU都使用一个。
:param random_state:随机数种子,默认为全局numpy随机数生成器
"""
from sklearn.cluster import KMeans
import numpy as np
X = np.array([[1, 2], [1, 4], [1, 0],[4, 2], [4, 4], [4, 0]])
kmeans = KMeans(n_clusters=2, random_state=0)
|
# 方法
fit(X,y=None)
使用 X 作为训练数据拟合模型
predict(X)
预测新的数据所在的类别
1
2
| kmeans.predict([[0, 0], [4, 4]])
array([0, 1], dtype=int32)
|
# 属性
cluster*centers*
集群中心的点坐标
1
2
3
| kmeans.cluster_centers_
array([[ 1., 2.],
[ 4., 2.]])
|
labels_
每个点的类别
# K-means ++
# 手写数字数据上 K-Means 聚类的演示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| from sklearn.metrics import silhouette_score
from sklearn.cluster import KMeans
def kmeans():
"""
手写数字聚类过程
:return: None
"""
# 加载数据
ld = load_digits()
print(ld.target[:20])
# 聚类
km = KMeans(n_clusters=810)
km.fit_transform(ld.data)
print(km.labels_[:20])
print(silhouette_score(ld.data,km.labels_))
return None
if __name__=="__main__":
kmeans()
|
=======
# 1. Scikit-learn 与特征工程
数据决定了机器学习的上限,而算法只是尽可能逼近这个上限”,这句话很好的阐述了数据在机器学习中的重要性。大部分直接拿过来的数据都是特征不明显的、没有经过处理的或者说是存在很多无用的数据,那么需要进行一些特征处理,特征的缩放等等,满足训练数据的要求。
我们将初次接触到 Scikit-learn 这个机器学习库的使用
Scikit-learn
- Python 语言的机器学习工具
- 所有人都适用,可在不同的上下文中重用
- 基于 NumPy、SciPy 和 matplotlib 构建
- 开源、商业可用 - BSD 许可
- 目前稳定版本 0.18
自 2007 年发布以来,scikit-learn 已经成为最给力的 Python 机器学习库(library)了。scikit-learn 支持的机器学习算法包括分类,回归,降维和聚类。还有一些特征提取(extracting features)、数据处理(processing data)和模型评估(evaluating models)的模块。作为 Scipy 库的扩展,scikit-learn 也是建立在 Python 的 NumPy 和 matplotlib 库基础之上。NumPy 可以让 Python 支持大量多维矩阵数据的高效操作,matplotlib 提供了可视化工具,SciPy 带有许多科学计算的模型。
scikit-learn 文档完善,容易上手,丰富的 API,使其在学术界颇受欢迎。开发者用 scikit-learn 实验不同的算法,只要几行代码就可以搞定。scikit-learn 包括许多知名的机器学习算法的实现,包括 LIBSVM 和 LIBLINEAR。还封装了其他的 Python 库,如自然语言处理的 NLTK 库。另外,scikit-learn 内置了大量数据集,允许开发者集中于算法设计,节省获取和整理数据集的时间。
安装的话参考下面步骤: 创建一个基于 Python3 的虚拟环境:
1
| mkvirtualenv -p /usr/local/bin/python3.6 ml3
|
在 ubuntu 的虚拟环境当中运行以下命令
1
| pip3 install Scikit-learn
|
然后通过导入命令查看是否可以使用:
# 数据的特征工程
从数据中抽取出来的对预测结果有用的信息,通过专业的技巧进行数据处理,是的特征能在机器学习算法中发挥更好的作用。优质的特征往往描述了数据的固有结构。 最初的原始特征数据集可能太大,或者信息冗余,因此在机器学习的应用中,一个初始步骤就是选择特征的子集,或构建一套新的特征集,减少功能来促进算法的学习,提高泛化能力和可解释性。
例如:你要查看不同地域女性的穿衣品牌情况,预测不同地域的穿衣品牌。如果其中含有一些男性的数据,是不是要将这些数据给去除掉
# 特征工程的意义
- 更好的特征意味着更强的鲁棒性
- 更好的特征意味着只需用简单模型
- 更好的特征意味着更好的结果
# 特征工程之特征处理
特征工程中最重要的一个环节就是特征处理,特征处理包含了很多具体的专业技巧
# 特征工程之特征抽取与特征选择
如果说特征处理其实就是在对已有的数据进行运算达到我们目标的数据标准。特征抽取则是将任意数据格式(例如文本和图像)转换为机器学习的数字特征。而特征选择是在已有的特征中选择更好的特征。后面会详细介绍特征选择主要区别于降维。
# 1.1 数据的来源与类型
大部分的数据都来自已有的数据库,如果没有的话也可以交给很多爬虫工程师去采集,来提供。也可以来自平时的记录,反正数据无处不在,大都是可用的。
# 数据的类型
按照机器学习的数据分类我们可以将数据分成:
- 标称型:标称型目标变量的结果只在有限目标集中取值,如真与假 (标称型目标变量主要用于分类)
- 数值型:数值型目标变量则可以从无限的数值集合中取值,如 0.100,42.001 等 (数值型目标变量主要用于回归分析)
按照数据的本身分布特性
那么什么是离散型和连续型数据呢?首先连续型数据是有规律的,离散型数据是没有规律的
- 离散变量是指其数值只能用自然数或整数单位计算的则为离散变量.例如,班级人数、进球个数、是否是某个类别等等
- 连续型数据是指在指定区间内可以是任意一个数值,例如,票房数据、花瓣大小分布数据
# 1.2 数据的特征抽取
现实世界中多数特征都不是连续变量,比如分类、文字、图像等,为了对非连续变量做特征表述,需要对这些特征做数学化表述,因此就用到了特征提取. sklearn.feature_extraction 提供了特征提取的很多方法
# 分类特征变量提取
我们将城市和环境作为字典数据,来进行特征的提取。
sklearn.feature_extraction.DictVectorizer(sparse = True)
将映射列表转换为 Numpy 数组或 scipy.sparse 矩阵
- sparse 是否转换为 scipy.sparse 矩阵表示,默认开启
方法
fit_transform(X,y)
应用并转化映射列表 X,y 为目标类型
inverse_transform(X[, dict_type])
将 Numpy 数组或 scipy.sparse 矩阵转换为映射列表
1
2
3
4
5
6
7
8
| from sklearn.feature_extraction import DictVectorizer
onehot = DictVectorizer() # 如果结果不用toarray,请开启sparse=False
instances = [{'city': '北京', 'temperature': 100}, {'city': '上海', 'temperature': 60},
{'city': '深圳', 'temperature': 30}]
X = onehot.fit_transform(instances).toarray()
print(onehot.inverse_transform(X))
print(onehot.get_feature_names())
print(X)
|
# 文本特征提取(只限于英文)
文本的特征提取应用于很多方面,比如说文档分类、垃圾邮件分类和新闻分类。那么文本分类是通过词是否存在、以及词的概率(重要性)来表示。
(1) 文档的中词的出现
数值为 1 表示词表中的这个词出现,为 0 表示未出现
sklearn.feature_extraction.text.CountVectorizer()
将文本文档的集合转换为计数矩阵(scipy.sparse matrices)
方法
fit_transform(raw_documents,y)
学习词汇词典并返回词汇文档矩阵
1
2
3
4
| from sklearn.feature_extraction.text import CountVectorizer
content = ["life is short,i like python","life is too long,i dislike python"]
vectorizer = CountVectorizer()
print(vectorizer.fit_transform(content).toarray())
|
需要 toarray() 方法转变为 numpy 的数组形式
温馨提示:每个文档中的词,只是整个语料库中所有词,的很小的一部分,这样造成特征向量的稀疏性(很多值为 0)为了解决存储和运算速度的问题,使用 Python 的 scipy.sparse 矩阵结构
(2)TF-IDF 表示词的重要性
TfidfVectorizer 会根据指定的公式将文档中的词转换为概率表示。(朴素贝叶斯介绍详细的用法)
class sklearn.feature_extraction.text.TfidfVectorizer()
方法
fit_transform(raw_documents,y)
学习词汇和 idf,返回术语文档矩阵。
1
2
3
4
5
| from sklearn.feature_extraction.text import TfidfVectorizer
content = ["life is short,i like python","life is too long,i dislike python"]
vectorizer = TfidfVectorizer(stop_words='english')
print(vectorizer.fit_transform(content).toarray())
print(vectorizer.vocabulary_)
|
# 文本特征提取(中文)
1
2
3
4
5
6
7
8
9
10
11
12
13
| def cutword():
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今。")
con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")
con3 = jieba.cut("如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
# 吧列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1, c2, c3
|
# 1.3 数据的特征预处理
# 单个特征
(1)归一化
归一化首先在特征(维度)非常多的时候,可以防止某一维或某几维对数据影响过大,也是为了把不同来源的数据统一到一个参考区间下,这样比较起来才有意义,其次可以程序可以运行更快。 例如:一个人的身高和体重两个特征,假如体重 50kg,身高 175cm,由于两个单位不一样,数值大小不一样。如果比较两个人的体型差距时,那么身高的影响结果会比较大,k- 临近算法会有这个距离公式。
min-max 方法
常用的方法是通过对原始数据进行线性变换把数据映射到 [0,1] 之间,变换的函数为:
其中 min 是样本中最小值,max 是样本中最大值,注意在数据流场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
sklearn.preprocessing.MinMaxScaler(feature_range=(0,1)…)
这里我们使用相亲约会对象数据在 MatchData.txt,这个样本时男士的数据,三个特征,玩游戏所消耗时间的百分比、每年获得的飞行常客里程数、每周消费的冰淇淋公升数。然后有一个 所属类别,被女士评价的三个类别,不喜欢、魅力一般、极具魅力。 首先导入数据进行矩阵转换处理.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import numpy as np
def data_matrix(file_name):
"""
将文本转化为matrix
:param file_name: 文件名
:return: 数据矩阵
"""
fr = open(file_name)
array_lines = fr.readlines()
number_lines = len(array_lines)
return_mat = zeros((number_lines, 3))
# classLabelVector = []
index = 0
for line in array_lines:
line = line.strip()
list_line = line.split('\t')
return_mat[index,:] = list_line[0:3]
# if(listFromLine[-1].isdigit()):
# classLabelVector.append(int(listFromLine[-1]))
# else:
# classLabelVector.append(love_dictionary.get(listFromLine[-1]))
# index += 1
return return_mat
|
输出结果为
1
2
3
4
5
6
7
| [[ 4.09200000e+04 8.32697600e+00 9.53952000e-01]
[ 1.44880000e+04 7.15346900e+00 1.67390400e+00]
[ 2.60520000e+04 1.44187100e+00 8.05124000e-01]
...,
[ 2.65750000e+04 1.06501020e+01 8.66627000e-01]
[ 4.81110000e+04 9.13452800e+00 7.28045000e-01]
[ 4.37570000e+04 7.88260100e+00 1.33244600e+00]]
|
我们查看数据集会发现,有的数值大到几万,有的才个位数,同样如果计算两个样本之间的距离时,其中一个影响会特别大。也就是说飞行里程数对于结算结果或者说相亲结果影响较大,但是统计的人觉得这三个特征同等重要,所以需要将数据进行这样的处理。
这样每个特征任意的范围将变成 [0,1] 的区间内的值,或者也可以根据需求处理到 [-1,1] 之间,我们再定义一个函数,进行这样的转换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| def feature_normal(data_set):
"""
特征归一化
:param data_set:
:return:
"""
# 每列最小值
min_vals = data_set.min(0)
# 每列最大值
max_vals = data_set.max(0)
ranges = max_vals - min_vals
norm_data = np.zeros(np.shape(data_set))
# 得出行数
m = data_set.shape[0]
# 矩阵相减
norm_data = data_set - np.tile(min_vals, (m,1))
# 矩阵相除
norm_data = norm_data/np.tile(ranges, (m, 1)))
return norm_data
|
输出结果为
1
2
3
4
5
6
7
| [[ 0.44832535 0.39805139 0.56233353]
[ 0.15873259 0.34195467 0.98724416]
[ 0.28542943 0.06892523 0.47449629]
...,
[ 0.29115949 0.50910294 0.51079493]
[ 0.52711097 0.43665451 0.4290048 ]
[ 0.47940793 0.3768091 0.78571804]]
|
这样得出的结果都非常相近,这样的数据可以直接提供测试验证了。
注意在特定场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
- min-max 的 scikit-learn 处理
scikit-learn.preprocessing 中的类 MinMaxScaler,将数据矩阵缩放到 [0,1] 之间
1
2
3
4
5
6
7
8
9
10
| >>> X_train = np.array([[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]])
...
>>> min_max_scaler = preprocessing.MinMaxScaler()
>>> X_train_minmax = min_max_scaler.fit_transform(X_train)
>>> X_train_minmax
array([[ 0.5 , 0. , 1. ],
[ 1. , 0.5 , 0.33333333],
[ 0. , 1. , 0. ]])
|
(3)标准化
特点:通过对原始数据进行变换把数据变换到均值为 0,方差为 1 范围内。
常用的方法是 z-score 标准化,经过处理后的数据均值为 0,标准差为 1,处理方法是:
其中μ是样本的均值,σ是样本的标准差,它们可以通过现有的样本进行估计,在已有的样本足够多的情况下比较稳定,适合嘈杂的数据场景。
sklearn 中提供了 StandardScalar 类实现列标准化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| In [2]: import numpy as np
In [3]: X_train = np.array([[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]])
In [4]: from sklearn.preprocessing import StandardScaler
In [5]: std = StandardScaler()
In [6]: X_train_std = std.fit_transform(X_train)
In [7]: X_train_std
Out[7]:
array([[ 0. , -1.22474487, 1.33630621],
[ 1.22474487, 0. , -0.26726124],
[-1.22474487, 1.22474487, -1.06904497]])
|
(3)缺失值
由于各种原因,许多现实世界的数据集包含缺少的值,通常编码为空白,NaN 或其他占位符。然而,这样的数据集与 scikit 的分类器不兼容,它们假设数组中的所有值都是数字,并且都具有和保持含义。使用不完整数据集的基本策略是丢弃包含缺失值的整个行和/或列。然而,这是以丢失可能是有价值的数据(即使不完整)的代价。更好的策略是估算缺失值,即从已知部分的数据中推断它们。
(1) 填充缺失值 使用 sklearn.preprocessing 中的 Imputer 类进行数据的填充 (旧 API)
新:from sklearn.impute import SimpleImputer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| class Imputer(sklearn.base.BaseEstimator, sklearn.base.TransformerMixin)
"""
用于完成缺失值的补充
:param param missing_values: integer or "NaN", optional (default="NaN")
丢失值的占位符,对于编码为np.nan的缺失值,使用字符串值“NaN”
:param strategy: string, optional (default="mean")
插补策略
如果是“平均值”,则使用沿轴的平均值替换缺失值
如果为“中位数”,则使用沿轴的中位数替换缺失值
如果“most_frequent”,则使用沿轴最频繁的值替换缺失
:param axis: integer, optional (default=0)
插补的轴
如果axis = 0,则沿列排列
如果axis = 1,则沿行排列
"""
>>> import numpy as np
>>> from sklearn.impute import SimpleImputer
>>> imp = Imputer(missing_values='NaN', strategy='mean')
>>> imp.fit([[1, 2], [np.nan, 3], [7, 6]])
Imputer(axis=0, copy=True, missing_values='NaN', strategy='mean', verbose=0)
>>> X = [[np.nan, 2], [6, np.nan], [7, 6]]
>>> print(imp.transform(X))
[[ 4. 2. ]
[ 6. 3.666...]
[ 7. 6. ]]
|
# 多个特征
# 降维
高维度数据容易出现的问题: 特征之间通常是线性相关的。
PCA(Principal component analysis),主成分分析。特点是保存数据集中对方差影响最大的那些特征,PCA 极其容易受到数据中特征范围影响,所以在运用 PCA 前一定要做特征标准化,这样才能保证每维度特征的重要性等同。
目的:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
作用:可以削减回归分析或者聚类分析中特征的数量
sklearn.decomposition.PCA
1
2
3
4
5
6
7
8
9
10
11
12
| class PCA(sklearn.decomposition.base)
"""
主成成分分析
:param n_components: int, float, None or string
这个参数可以帮我们指定希望PCA降维后的特征维度数目。最常用的做法是直接指定降维到的维度数目,此时n_components是一个大于1的整数。
我们也可以用默认值,即不输入n_components,此时n_components=min(样本数,特征数)
:param whiten: bool, optional (default False)
判断是否进行白化。所谓白化,就是对降维后的数据的每个特征进行归一化。对于PCA降维本身来说一般不需要白化,如果你PCA降维后有后续的数据处理动作,可以考虑白化,默认值是False,即不进行白化
:param svd_solver:
选择一个合适的SVD算法来降维,一般来说,使用默认值就够了。
"""
|
通过一个例子来看
1
2
3
4
5
6
7
8
9
| import numpy as np
from sklearn.decomposition import PCA
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
pca = PCA(n_components=2)
pca.fit(X)
PCA(copy=True, iterated_power='auto', n_components=2, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)
print(pca.explained_variance_ratio_)
# [ 0.99244... 0.00755...]
|
# 1.4 数据的特征选择
降维本质上是从一个维度空间映射到另一个维度空间,特征的多少别没有减少,当然在映射的过程中特征值也会相应的变化。举个例子,现在的特征是 1000 维,我们想要把它降到 500 维。降维的过程就是找个一个从 1000 维映射到 500 维的映射关系。原始数据中的 1000 个特征,每一个都对应着降维后的 500 维空间中的一个值。假设原始特征中有个特征的值是 9,那么降维后对应的值可能是 3。而对于特征选择来说,有很多方法:
- Filter(过滤式):VarianceThreshold
- Embedded(嵌入式):正则化、决策树
- Wrapper(包裹式)
其中过滤式的特征选择后,数据本身不变,而数据的维度减少。而嵌入式的特征选择方法也会改变数据的值,维度也改变。Embedded 方式是一种自动学习的特征选择方法,后面讲到具体的方法的时候就能理解了。
特征选择主要有两个功能:
(1)减少特征数量,降维,使模型泛化能力更强,减少过拟合
(2)增强特征和特征值之间的理解
sklearn.feature_selection
去掉取值变化小的特征(删除低方差特征)
VarianceThreshold 是特征选择中的一项基本方法。它会移除所有方差不满足阈值的特征。默认设置下,它将移除所有方差为 0 的特征,即那些在所有样本中数值完全相同的特征。
假设我们要移除那些超过 80% 的数据都为 1 或 0 的特征:
1
2
3
4
5
6
7
8
| VarianceThreshold(threshold = 0.0)
删除所有低方差特征
Variance.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:训练集差异低于threshold的特征将被删除。
默认值是保留所有非零方差特征,即删除所有样本
中具有相同值的特征。
|
1
2
3
4
5
6
7
8
9
10
| from sklearn.feature_selection import VarianceThreshold
X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]]
sel = VarianceThreshold(threshold=(.8 * (1 - .8)))
sel.fit_transform(X)
array([[0, 1],
[1, 0],
[0, 0],
[1, 1],
[1, 0],
[1, 1]])
|
# 2. Sklearn 数据集与机器学习组成
# 机器学习组成:模型、策略、优化
《统计机器学习》中指出:机器学习=模型 + 策略 + 算法。其实机器学习可以表示为:Learning= Representation+Evalution+Optimization。我们就可以将这样的表示和李航老师的说法对应起来。机器学习主要是由三部分组成,即:表示 (模型)、评价 (策略) 和优化 (算法)。
表示 (或者称为:模型):Representation
表示主要做的就是建模,故可以称为模型。模型要完成的主要工作是转换:将实际问题转化成为计算机可以理解的问题,就是我们平时说的建模。类似于传统的计算机学科中的算法,数据结构,如何将实际的问题转换成计算机可以表示的方式。这部分可以见“简单易学的机器学习算法”。给定数据,我们怎么去选择对应的问题去解决,选择正确的已有的模型是重要的一步。
评价 (或者称为:策略):Evalution
评价的目标是判断已建好的模型的优劣。对于第一步中建好的模型,评价是一个指标,用于表示模型的优劣。这里就会是一些评价的指标以及一些评价函数的设计。在机器学习中会有针对性的评价指标。
优化:Optimization
优化的目标是评价的函数,我们是希望能够找到最好的模型,也就是说评价最高的模型。
# 开发机器学习应用程序的步骤
(1)收集数据
我们可以使用很多方法收集样本护具,如:制作网络爬虫从网站上抽取数据、从 RSS 反馈或者 API 中得到信息、设备发送过来的实测数据。
(2)准备输入数据
得到数据之后,还必须确保数据格式符合要求。
(3)分析输入数据
这一步的主要作用是确保数据集中没有垃圾数据。如果是使用信任的数据来源,那么可以直接跳过这个步骤
(4)训练算法
机器学习算法从这一步才真正开始学习。如果使用无监督学习算法,由于不存在目标变量值,故而也不需要训练算法,所有与算法相关的内容在第(5)步
(5)测试算法
这一步将实际使用第(4)步机器学习得到的知识信息。当然在这也需要评估结果的准确率,然后根据需要重新训练你的算法
(6)使用算法
转化为应用程序,执行实际任务。以检验上述步骤是否可以在实际环境中正常工作。如果碰到新的数据问题,同样需要重复执行上述的步骤
# 2.1 Scikit-learn 数据集
我们将介绍 sklearn 中的数据集类,模块包括用于加载数据集的实用程序,包括加载和获取流行参考数据集的方法。它还具有一些人工数据生成器。
# sklearn.datasets
(1)datasets.load_*()
获取小规模数据集,数据包含在 datasets 里
(2)datasets.fetch_*()
获取大规模数据集,需要从网络上下载,函数的第一个参数是 data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/,要修改默认目录,可以修改环境变量 SCIKIT_LEARN_DATA
(3)datasets.make_*()
本地生成数据集
load*和 fetch* 函数返回的数据类型是 datasets.base.Bunch,本质上是一个 dict,它的键值对可用通过对象的属性方式访问。主要包含以下属性:
- data:特征数据数组,是 n_samples * n_features 的二维 numpy.ndarray 数组
- target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR:数据描述
- feature_names:特征名
- target_names:标签名
数据集目录可以通过 datasets.get_data_home() 获取,clear_data_home(data_home=None) 删除所有下载数据
(4)datasets.get_data_home(data_home=None)
返回 scikit 学习数据目录的路径。这个文件夹被一些大的数据集装载器使用,以避免下载数据。默认情况下,数据目录设置为用户主文件夹中名为“scikit_learn_data”的文件夹。或者,可以通过“SCIKIT_LEARN_DATA”环境变量或通过给出显式的文件夹路径以编程方式设置它。’〜’ 符号扩展到用户主文件夹。如果文件夹不存在,则会自动创建。
(5)sklearn.datasets.clear_data_home(data_home=None)
删除存储目录中的数据
# 获取小数据集
用于分类
- sklearn.datasets.load_iris
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| class sklearn.datasets.load_iris(return_X_y=False)
"""
加载并返回虹膜数据集
:param return_X_y: 如果为True,则返回而不是Bunch对象,默认为False
:return: Bunch对象,如果return_X_y为True,那么返回tuple,(data,target)
"""
In [12]: from sklearn.datasets import load_iris
...: data = load_iris()
...:
In [13]: data.target
Out[13]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
In [14]: data.feature_names
Out[14]:
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
In [15]: data.target_names
Out[15]:
array(['setosa', 'versicolor', 'virginica'],
dtype='|S10')
In [17]: data.targetspan>
Out[17]: array([0, 0, 2])
|
| 名称 | 数量 |
|---|
| 类别 | 3 |
| 特征 | 4 |
| 样本数量 | 150 |
| 每个类别数量 | 50 |
- sklearn.datasets.load_digits
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| class sklearn.datasets.load_digits(n_class=10, return_X_y=False)
"""
加载并返回数字数据集
:param n_class: 整数,介于0和10之间,可选(默认= 10,要返回的类的数量
:param return_X_y: 如果为True,则返回而不是Bunch对象,默认为False
:return: Bunch对象,如果return_X_y为True,那么返回tuple,(data,target)
"""
In [20]: from sklearn.datasets import load_digits
In [21]: digits = load_digits()
In [22]: print(digits.data.shape)
(1797, 64)
In [23]: digits.target
Out[23]: array([0, 1, 2, ..., 8, 9, 8])
In [24]: digits.target_names
Out[24]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [25]: digits.images
Out[25]:
array([[[ 0., 0., 5., ..., 1., 0., 0.],
[ 0., 0., 13., ..., 15., 5., 0.],
[ 0., 3., 15., ..., 11., 8., 0.],
...,
[ 0., 4., 11., ..., 12., 7., 0.],
[ 0., 2., 14., ..., 12., 0., 0.],
[ 0., 0., 6., ..., 0., 0., 0.]],
[[ 0., 0., 10., ..., 1., 0., 0.],
[ 0., 2., 16., ..., 1., 0., 0.],
[ 0., 0., 15., ..., 15., 0., 0.],
...,
[ 0., 4., 16., ..., 16., 6., 0.],
[ 0., 8., 16., ..., 16., 8., 0.],
[ 0., 1., 8., ..., 12., 1., 0.]]])
|
用于回归
- sklearn.datasets.load_boston
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| class sklearn.datasets.load_boston(return_X_y=False)
"""
加载并返回波士顿房价数据集
:param return_X_y: 如果为True,则返回而不是Bunch对象,默认为False
:return: Bunch对象,如果return_X_y为True,那么返回tuple,(data,target)
"""
In [34]: from sklearn.datasets import load_boston
In [35]: boston = load_boston()
In [36]: boston.data.shape
Out[36]: (506, 13)
In [37]: boston.feature_names
Out[37]:
array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'],
dtype='|S7')
In [38]:
|
- sklearn.datasets.load_diabetes
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| class sklearn.datasets.load_diabetes(return_X_y=False)
"""
加载和返回糖尿病数据集
:param return_X_y: 如果为True,则返回而不是Bunch对象,默认为False
:return: Bunch对象,如果return_X_y为True,那么返回tuple,(data,target)
"""
In [13]: from sklearn.datasets import load_diabetes
In [14]: diabetes = load_diabetes()
In [15]: diabetes.data
Out[15]:
array([[ 0.03807591, 0.05068012, 0.06169621, ..., -0.00259226,
0.01990842, -0.01764613],
[-0.00188202, -0.04464164, -0.05147406, ..., -0.03949338,
-0.06832974, -0.09220405],
[ 0.08529891, 0.05068012, 0.04445121, ..., -0.00259226,
0.00286377, -0.02593034],
...,
[ 0.04170844, 0.05068012, -0.01590626, ..., -0.01107952,
-0.04687948, 0.01549073],
[-0.04547248, -0.04464164, 0.03906215, ..., 0.02655962,
0.04452837, -0.02593034],
[-0.04547248, -0.04464164, -0.0730303 , ..., -0.03949338,
-0.00421986, 0.00306441]])
|
| 名称 | 数量 |
|---|
| 目标范围 | 25-346 |
| 特征 | 10 |
| 样本数量 | 442 |
# 获取大数据集
- sklearn.datasets.fetch_20newsgroups
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| class sklearn.datasets.fetch_20newsgroups(data_home=None, subset='train', categories=None, shuffle=True, random_state=42, remove=(), download_if_missing=True)
"""
加载20个新闻组数据集中的文件名和数据
:param subset: 'train'或者'test','all',可选,选择要加载的数据集:训练集的“训练”,测试集的“测试”,两者的“全部”,具有洗牌顺序
:param data_home: 可选,默认值:无,指定数据集的下载和缓存文件夹。如果没有,所有scikit学习数据都存储在'〜/ scikit_learn_data'子文件夹中
:param categories: 无或字符串或Unicode的集合,如果没有(默认),加载所有类别。如果不是无,要加载的类别名称列表(忽略其他类别)
:param shuffle: 是否对数据进行洗牌
:param random_state: numpy随机数生成器或种子整数
:param download_if_missing: 可选,默认为True,如果False,如果数据不在本地可用而不是尝试从源站点下载数据,则引发IOError
:param remove: 元组
"""
In [29]: from sklearn.datasets import fetch_20newsgroups
In [30]: data_test = fetch_20newsgroups(subset='test',shuffle=True, random_sta
...: te=42)
In [31]: data_train = fetch_20newsgroups(subset='train',shuffle=True, random_s
...: tate=42)
|
- sklearn.datasets.fetch_20newsgroups_vectorized
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| class sklearn.datasets.fetch_20newsgroups_vectorized(subset='train', remove=(), data_home=None)
"""
加载20个新闻组数据集并将其转换为tf-idf向量,这是一个方便的功能; 使用sklearn.feature_extraction.text.Vectorizer的默认设置完成tf-idf 转换。对于更高级的使用(停止词过滤,n-gram提取等),将fetch_20newsgroup与自定义Vectorizer或CountVectorizer组合在一起
:param subset: 'train'或者'test','all',可选,选择要加载的数据集:训练集的“训练”,测试集的“测试”,两者的“全部”,具有洗牌顺序
:param data_home: 可选,默认值:无,指定数据集的下载和缓存文件夹。如果没有,所有scikit学习数据都存储在'〜/ scikit_learn_data'子文件夹中
:param remove: 元组
"""
In [57]: from sklearn.datasets import fetch_20newsgroups_vectorized
In [58]: bunch = fetch_20newsgroups_vectorized(subset='all')
In [59]: from sklearn.utils import shuffle
In [60]: X, y = shuffle(bunch.data, bunch.target)
...: offset = int(X.shape[0] * 0.8)
...: X_train, y_train = X[:offset], y[:offset]
...: X_test, y_test = X[offset:], y[offset:]
...:
|
# 获取本地生成数据
生成本地分类数据:
1
2
| from sklearn.datasets.samples_generator import make_classification
X,y= datasets.make_classification(n_samples=100000, n_features=20,n_informative=2, n_redundant=10,random_state=42)
|
生成本地回归数据:
- sklearn.datasets.make_regression
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| class make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)
"""
生成用于回归的数据集
:param n_samples:int,optional(default = 100),样本数量
:param n_features:int,optional(default = 100),特征数量
:param coef:boolean,optional(default = False),如果为True,则返回底层线性模型的系数
:param random_state:int,RandomState实例或无,可选(默认=无)
如果int,random_state是随机数生成器使用的种子; 如果RandomState的实例,random_state是随机数生成器; 如果没有,随机数生成器所使用的RandomState实例np.random
:return :X,特征数据集;y,目标值
"""
from sklearn.datasets.samples_generator import make_regression
X, y = make_regression(n_samples=200, n_features=5000, random_state=42)
|
# 2.2 模型的选择
算法是核心,数据和计算是基础。这句话很好的说明了机器学习中算法的重要性。那么我们开看下机器学习的几种分类:
- 监督学习
- 分类 k- 近邻算法、决策树、贝叶斯、逻辑回归 (LR)、支持向量机 (SVM)
- 回归 线性回归、岭回归
- 标注 隐马尔可夫模型 (HMM)
- 无监督学习
# 如何选择合适的算法模型
在解决问题的时候,必须考虑下面两个问题:一、使用机器学习算法的目的,想要算法完成何种任务,比如是预测明天下雨的概率是对投票者按照兴趣分组;二、需要分析或者收集的数据时什么
首先考虑使用机器学习算法的目的。如果想要预测目标变量的值,则可以选择监督学习算法,否则可以选择无监督学习算法,确定选择监督学习算法之后,需要进一步确定目标变量类型,如果目标变量是离散型,如是/否、1/2/3,A/B/C/或者红/黑/黄等,则可以选择分类算法;如果目标变量是连续的数值,如 0.0~100.0、-999~999 等,则需要选择回归算法
如果不想预测目标变量的值,则可以选择无监督算法。进一步分析是否需要将数据划分为离散的组。如果这是唯一的需求,则使用聚类算法。
当然在大多数情况下,上面给出的选择办法都能帮助读者选择恰当的机器学习算法,但这也并非已成不变。也有分类算法可以用于回归。
其次考虑的是数据问题,我们应该充分了解数据,对实际数据了解的越充分,越容易创建符合实际需求的应用程序,主要应该了解数据的一下特性:特征值是离散型变量 还是 连续型变量 ,特征值中是否存在缺失的值,何种原因造成缺失值,数据中是够存在异常值,某个特征发生的频率如何,等等。充分了解上面提到的这些数据特性可以缩短选择机器学习算法的时间。
# 监督学习中三类问题的解释
(1)分类问题 分类是监督学习的一个核心问题,在监督学习中,当输出变量取有限个离散值时,预测问题变成为分类问题。这时,输入变量可以是离散的,也可以是连续的。监督学习从数据中学习一个分类模型活分类决策函数,称为分类器。分类器对新的输入进行输出的预测,称为分类。最基础的便是二分类问题,即判断是非,从两个类别中选择一个作为预测结果;除此之外还有多酚类的问题,即在多于两个类别中选择一个。
分类问题包括学习和分类两个过程,在学习过程中,根据已知的训练数据集利用有效的学习方法学习一个分类器,在分类过程中,利用学习的分类器对新的输入实例进行分类。图中 (X1,Y1),(X2,Y2)…都是训练数据集,学习系统有训练数据学习一个分类器 P(Y|X) 或 Y=f(X); 分类系统通过学习到的分类器对于新输入的实例子 Xn+1 进行分类,即预测术其输出的雷标记 Yn+1
分类在于根据其特性将数据“分门别类”,所以在许多领域都有广泛的应用。例如,在银行业务中,可以构建一个客户分类模型,按客户按照贷款风险的大小进行分类;在网络安全领域,可以利用日志数据的分类对非法入侵进行检测;在图像处理中,分类可以用来检测图像中是否有人脸出现;在手写识别中,分类可以用于识别手写的数字;在互联网搜索中,网页的分类可以帮助网页的抓取、索引和排序。
即一个分类应用的例子,文本分类。这里的文本可以是新闻报道、网页、电子邮件、学术论文。类别往往是关于文本内容的。例如政治、体育、经济等;也有关于文本特点的,如正面意见、反面意见;还可以根据应用确定,如垃圾邮件、非垃圾邮件等。文本分类是根据文本的特征将其划分到已有的类中。输入的是文本的特征向量,输出的是文本的类别。通常把文本的单词定义出现取值是 1,否则是 0;也可以是多值的,,表示单词在文本中出现的频率。直观地,如果“股票”“银行““货币”这些词出现很多,这个文本可能属于经济学,如果“网球””比赛“”运动员“这些词频繁出现,这个文本可能属于体育类。
(2)回归问题
回归是监督学习的另一个重要问题。回归用于预测输入变量和输出变量之间的关系,特别是当初如变量的值发生变化时,输出变量的值随之发生的变化。回归模型正式表示从输入到输出变量之间映射的函数。回归稳日的学习等价与函数拟合:选择一条函数曲线使其更好的拟合已知数据且很好的预测位置数据
回归问题按照输入变量的个数,分为一元回归和多元回归;按照输入变量和输出变量之间关系的类型即模型的类型,分为线性回归和非线性回归。
许多领域的任务都可以形式化为回归问题,比如,回归可以用于商务领域,作为市场趋势预测、产品质量管理、客户满意度调查、偷袭风险分析的工具。
(3)标注问题
标注也是一个监督学习问题。可以认为标注问题是分类问题的一个推广,标注问题又是更复杂的结构预测问题的简单形式。标注问题的输入是一个观测序列,输出是一个标记序列或状态序列。标注问题在信息抽取、自然语言处理等领域广泛应用,是这些领域的基本问题。例如,自然语言处理的词性标注就是一个典型的标注,即对一个单词序列预测其相应的词性标记序
当然我们主要关注的是分类和回归问题,并且标注问题的算法复杂
# 2.3 模型检验 - 交叉验证
一般在进行模型的测试时,我们会将数据分为训练集和测试集。在给定的样本空间中,拿出大部分样本作为训练集来训练模型,剩余的小部分样本使用刚建立的模型进行预测。
# 训练集与测试集
训练集与测试集的分割可以使用 cross_validation 中的 train_test_split 方法,大部分的交叉验证迭代器都内建一个划分数据前进行数据索引打散的选项,train_test_split 方法内部使用的就是交叉验证迭代器。默认不会进行打散,包括设置 cv=some_integer(直接)k 折叠交叉验证的 cross_val_score 会返回一个随机的划分。如果数据集具有时间性,千万不要打散数据再划分!
- sklearn.cross_validation.train_test_split
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| def train_test_split(*arrays,**options)
"""
:param arrays:允许的输入是列表,数字阵列
:param test_size:float,int或None(默认为无),如果浮点数应在0.0和1.0之间,并且表示要包括在测试拆分中的数据集的比例。如果int,表示测试样本的绝对数
:param train_size:float,int或None(默认为无),如果浮点数应在0.0到1.0之间,表示数据集包含在列车拆分中的比例。如果int,表示列车样本的绝对数
:param random_state:int或RandomState,用于随机抽样的伪随机数发生器状态,参数 random_state 默认设置为 None,这意为着每次打散都是不同的。
"""
from sklearn.cross_validation import train_test_split
from sklearn import datasets
iris = datasets.load_iris()
print iris.data.shape,iris.target.shape
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.4, random_state=42)
print X_train.shape,y_train.shape
print X_test.shape,y_test.shape
|
上面的方式也有局限。因为只进行一次测试,并不一定能代表模型的真实准确率。因为,模型的准确率和数据的切分有关系,在数据量不大的情况下,影响尤其突出。所以还需要一个比较好的解决方案。
模型评估中,除了训练数据和测试数据,还会涉及到验证数据。使用训练数据与测试数据进行了交叉验证,只有这样训练出的模型才具有更可靠的准确率,也才能期望模型在新的、未知的数据集上,能有更好的表现。这便是模型的推广能力,也即泛化能力的保证。
# Holdout Method
评估模型泛化能力的典型方法是 holdout 交叉验证 (holdout cross validation)。holdout 方法很简单,我们只需要将原始数据集分割为训练集和测试集,前者用于训练模型,后者用于评估模型的性能。一般来说,Holdout 验证并非一种交叉验证,因为数据并没有交叉使用。 随机从最初的样本中选出部分,形成交叉验证数据,而剩余的就当做训练数据。 一般来说,少于原本样本三分之一的数据被选做验证数据。所以这种方法得到的结果其实并不具有说服性
# K- 折交叉验证
K 折交叉验证,初始采样分割成 K 个子样本,一个单独的子样本被保留作为验证模型的数据,其他 K-1 个样本用来训练。交叉验证重复 K 次,每个子样本验证一次,平均 K 次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10 折交叉验证是最常用的。
例如 5 折交叉验证,全部可用数据集分成五个集合,每次迭代都选其中的 1 个集合数据作为验证集,另外 4 个集合作为训练集,经过 5 组的迭代过程。交叉验证的好处在于,可以保证所有数据都有被训练和验证的机会,也尽最大可能让优化的模型性能表现的更加可信。
使用交叉验证的最简单的方法是在估计器和数据集上使用 cross_val_score 函数。
- sklearn.cross_validation.cross_val_score
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| def cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
"""
:param estimator:模型估计器
:param X:特征变量集合
:param y:目标变量
:param cv:int,使用默认的3折交叉验证,整数指定一个(分层)KFold中的折叠数
:return :预估系数
"""
from sklearn.cross_validation import cross_val_score
diabetes = datasets.load_diabetes()
X = diabetes.data[:150]
y = diabetes.target[:150]
lasso = linear_model.Lasso()
print(cross_val_score(lasso, X, y))
|
使用交叉验证方法的目的主要有 2 个:
- 从有限的学习数据中获取尽可能多的有效信息;
- 可以在一定程度上避免过拟合问题。
# 超参数搜索 - 网格搜索
通常情况下,有很多参数是需要手动指定的(如 k- 近邻算法中的 K 值),
这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组
合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建
立模型。
sklearn.model_selection.GridSearchCV
# 2.4 Estimator 的工作流程
在 sklearn 中,估计器 (estimator) 是一个重要的角色,分类器和回归器都属于 estimator。在估计器中有有两个重要的方法是 fit 和 transform。
- fit 方法用于从训练集中学习模型参数
- transform 用学习到的参数转换数据
# 3. Scikit-learn 的分类器算法
# 3.1 分类算法之 K- 近邻
定义:如果一个样本在特征空间中的 k 个最相似 (即特征空间中最邻近) 的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN 算法最早是由 Cover 和 Hart 提出的一种分类算法。
k- 近邻算法采用测量不同特征值之间的距离来进行分类
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高,必须指定 K 值,K 值选择不当则分类精度不能保证
使用数据范围:数值型和标称型
加快搜索速度——基于算法的改进 KDTree,API 接口里面有实现
# 一个例子弄懂 K- 近邻
电影可以按照题材分类,每个题材又是如何定义的呢?那么假如两种类型的电影,动作片和爱情片。动作片有哪些公共的特征?那么爱情片又存在哪些明显的差别呢?我们发现动作片中打斗镜头的次数较多,而爱情片中接吻镜头相对更多。当然动作片中也有一些接吻镜头,爱情片中也会有一些打斗镜头。所以不能单纯通过是否存在打斗镜头或者接吻镜头来判断影片的类别。那么现在我们有 6 部影片已经明确了类别,也有打斗镜头和接吻镜头的次数,还有一部电影类型未知。
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|
| California Man | 3 | 104 | 爱情片 |
| He’s not Really into dues | 2 | 100 | 爱情片 |
| Beautiful Woman | 1 | 81 | 爱情片 |
| Kevin Longblade | 101 | 10 | 动作片 |
| Robo Slayer 3000 | 99 | 5 | 动作片 |
| Amped II | 98 | 2 | 动作片 |
| ? | 18 | 90 | 未知 |
那么我们使用 K- 近邻算法来分类爱情片和动作片:存在一个样本数据集合,也叫训练样本集,样本个数 M 个,知道每一个数据特征与类别对应关系,然后存在未知类型数据集合 1 个,那么我们要选择一个测试样本数据中与训练样本中 M 个的距离,排序过后选出最近的 K 个,这个取值一般不大于 20 个。选择 K 个最相近数据中次数最多的分类。那么我们根据这个原则去判断未知电影的分类
| 电影名称 | 与未知电影的距离 |
|---|
| California Man | 20.5 |
| He’s not Really into dues | 18.7 |
| Beautiful Woman | 19.2 |
| Kevin Longblade | 115.3 |
| Robo Slayer 3000 | 117.4 |
| Amped II | 118.9 |
我们假设 K 为 3,那么排名前三个电影的类型都是爱情片,所以我们判定这个未知电影也是一个爱情片。那么计算距离是怎样计算的呢?
# sklearn.neighbors
sklearn.neighbors 提供监督的基于邻居的学习方法的功能,sklearn.neighbors.KNeighborsClassifier 是一个最近邻居分类器。那么 KNeighborsClassifier 是一个类,我们看一下实例化时候的参数
1
2
3
4
5
6
7
8
9
10
11
12
13
| class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1, **kwargs)**
"""
:param n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
:param algorithm:{'auto','ball_tree','kd_tree','brute'},可选用于计算最近邻居的算法:'ball_tree'将会使用 BallTree,'kd_tree'将使用 KDTree,“野兽”将使用强力搜索。'auto'将尝试根据传递给fit方法的值来决定最合适的算法。
:param n_jobs:int,可选(默认= 1),用于邻居搜索的并行作业数。如果-1,则将作业数设置为CPU内核数。不影响fit方法。
"""
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
neigh = KNeighborsClassifier(n_neighbors=3)
|
# Method
fit(X, y)
使用 X 作为训练数据拟合模型,y 作为 X 的类别值。X,y 为数组或者矩阵
1
2
3
| X = np.array([[1,1],[1,1.1],[0,0],[0,0.1]])
y = np.array([1,1,0,0])
neigh.fit(X,y)
|
kneighbors(X=None, n_neighbors=None, return_distance=True)
找到指定点集 X 的 n_neighbors 个邻居,return_distance 为 False 的话,不返回距离
1
2
3
| neigh.kneighbors(np.array(span>),return_distance= False)
neigh.kneighbors(np.array(span>),return_distance= False,an_neighbors=2)
|
predict(X)
预测提供的数据的类标签
1
| neigh.predict(np.array([[0.1,0.1],[1.1,1.1]]))
|
predict_proba(X)
返回测试数据 X 属于某一类别的概率估计
1
| neigh.predict_proba(np.array(span>))
|
# 3.2 K- 近邻算法案例分析
本案例使用最著名的”鸢尾“数据集,该数据集曾经被 Fisher 用在经典论文中,目前作为教科书般的数据样本预存在 Scikit-learn 的工具包中。
读入 Iris 数据集细节资料
1
2
3
4
5
6
7
8
9
| from sklearn.datasets import load_iris
# 使用加载器读取数据并且存入变量iris
iris = load_iris()
# 查验数据规模
iris.data.shape
# 查看数据说明(这是一个好习惯)
print iris.DESCR
|
通过上述代码对数据的查验以及数据本身的描述,我们了解到 Iris 数据集共有 150 朵鸢尾数据样本,并且均匀分布在 3 个不同的亚种;每个数据样本有总共 4 个不同的关于花瓣、花萼的形状特征所描述。由于没有制定的测试集合,因此按照惯例,我们需要对数据进行随即分割,25% 的样本用于测试,其余 75% 的样本用于模型的训练。
由于不清楚数据集的排列是否随机,可能会有按照类别去进行依次排列,这样训练样本的不均衡的,所以我们需要分割数据,已经默认有随机采样的功能。
对 Iris 数据集进行分割
1
2
| from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.25,random_state=42)
|
对特征数据进行标准化
1
2
3
4
5
| from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.fit_transform(X_test)
|
K 近邻算法是非常直观的机器学习模型,我们可以发现 K 近邻算法没有参数训练过程,也就是说,我们没有通过任何学习算法分析训练数据,而只是根据测试样本训练数据的分布直接作出分类决策。因此,K 近邻属于无参数模型中非常简单一种。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| from sklearn.datasets import load_iris
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import GridSearchCV
def knniris():
"""
鸢尾花分类
:return: None
"""
# 数据集获取和分割
lr = load_iris()
x_train, x_test, y_train, y_test = train_test_split(lr.data, lr.target, test_size=0.25)
# 进行标准化
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# estimator流程
knn = KNeighborsClassifier()
# # 得出模型
# knn.fit(x_train,y_train)
#
# # 进行预测或者得出精度
# y_predict = knn.predict(x_test)
#
# # score = knn.score(x_test,y_test)
# 通过网格搜索,n_neighbors为参数列表
param = {"n_neighbors": [3, 5, 7]}
gs = GridSearchCV(knn, param_grid=param, cv=10)
# 建立模型
gs.fit(x_train,y_train)
# print(gs)
# 预测数据
print(gs.score(x_test,y_test))
# 分类模型的精确率和召回率
# print("每个类别的精确率与召回率:",classification_report(y_test, y_predict,target_names=lr.target_names))
return None
if __name__ == "__main__":
knniris()
|
# 3.3 朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一个非常简单,但是实用性很强的分类模型。朴素贝叶斯分类器的构造基础是贝叶斯理论。
# 概率论基础
概率定义为一件事情发生的可能性。事情发生的概率可以 通过观测数据中的事件发生次数来计算,事件发生的概率等于改事件发生次数除以所有事件发生的总次数。举一些例子:
- 扔出一个硬币,结果头像朝上
- 某天是晴天
- 某个单词在未知文档中出现
我们将事件的概率记作 P(X),那么假设这一事件为 X 属于样本空间中的一个类别,那么 0≤P(X)≤1。
联合概率与条件概率
是指两件事情同时发生的概率。那么我们假设样本空间有一些天气数据:
| 编号 | 星期几 | 天气 |
|---|
| 1 | 2 | 晴天 |
| 2 | 1 | 下雨 |
| 3 | 3 | 晴天 |
| 4 | 4 | 晴天 |
| 5 | 1 | 下雨 |
| 6 | 2 | 下雪 |
| 7 | 3 | 下雪 |
那么天气被分成了三类,那么 P(X=sun)=3/7,假如说天气=下雪且星期几=2?这个概率怎么求?这个概率应该等于两件事情为真的次数除以所有事件发生 的总次数。我们可以看到只有一个样本满足天气=下雪且星期几=2,所以这个概率为 1/7。一般对于 X 和 Y 来说,对应的联合概率记为 P(XY)。
那么条件概率形如 P(X∣Y),这种格式的。表示为在 Y 发生的条件下,发生 X 的概率。假设 X 代表星期,Y 代表天气,则 P(X=3∣Y=sun) 如何求?
从表中我们可以得出,P(X=3,Y=sun)=1/7,P(Y)=3/7。
P(X=3∣Y=sun)=1/3=P(X=3,Y=sun)/P(Y)
在条件概率中,有一个重要的特性
那么则有
这个式子的意思是给定条件下,所有的 X 的概率为单独的 Y 条件下每个 X 发生的概率乘积,我们通过后面再继续去理解这个式子的具体含义。
贝叶斯公式
首先我们给出该公式的表示,
,其中 ci 为类别,W 为特征向量。
贝叶斯公式最常用于文本分类,上式左边可以理解为给定一个文本词向量 W,那么它属于类别 ci 的概率是多少。那么式子右边分几部分,P(W∣ci) 理解为在给定类别的情况下,该文档的词向量的概率。可以通过条件概率中的重要特性来求解。
假设我们有已分类的文档,
1
2
3
4
| a = "life is short,i like python"
b = "life is too long,i dislike python"
c = "yes,i like python"
label=[1,0,1]
|
词袋法的特征值计算
若使用词袋法,且以训练集中的文本为词汇表,即将训练集中的文本中出现的单词 (不重复) 都统计出来作为词典,那么记单词的数目为 n,这代表了文本的 n 个维度。以上三个文本在这 8 个特征维度上的表示为:
| life | is | i | short | long | like | dislike | too | python | yes |
|---|
| a' | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| b' | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 |
| c' | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
上面 a’,b’ 就是两个文档的词向量的表现形式,对于贝叶斯公式,从 label 中我们可以得出两个类别的概率为:
对于一个给定的文档类别,每个单词特征向量的概率是多少呢?
提供一种 TF 计算方法,为类别 yk 每个单词出现的次数 Ni,除以文档类别 yk 中所有单词出现次数的总数 N:
Pi=Ni/N
首先求出现总数,对于 1 类别文档,在 a’ 中,就可得出总数为 1+1+1+1+1+1=6,c’ 中,总共 1+1+1+1=4,故在 1 类别文档中总共有 10 次。
每个单词出现总数,假设是两个列表,a’+c’ 就能得出每个单词出现次数,比如 P(w=python)=2/10=0.20000000,同样可以得到其它的单词概率。最终结果如下:
1
2
3
4
| # 类别1文档中的词向量概率
p1 = [0.10000000,0.10000000,0.20000000,0.10000000,0,0.20000000,0,0,0.20000000,0.10000000]
# 类别0文档中的词向量概率
p0 = [0.16666667,0.16666667,0.16666667,0,0.16666667,0,0.16666667,0.16666667,0.16666667,0]
|
拉普拉斯平滑系数
为了避免训练集样本对一些特征的缺失,即某一些特征出现的次数为 0,在计算 P(X1,X2,X3,…,Xn∣Yi) 的时候,各个概率相乘最终结果为零,这样就会影响结果。我们需要对这个概率计算公式做一个平滑处理:
其中 m 为特征词向量的个数,α为平滑系数,当α=1,称为拉普拉斯平滑。
# sklearn.naive_bayes.MultinomialNB
1
2
3
4
| class sklearn.naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)
"""
:param alpha:float,optional(default = 1.0)加法(拉普拉斯/ Lidstone)平滑参数(0为无平滑)
"""
|
# 互联网新闻分类
读取 20 类新闻文本的数据细节
1
2
3
4
5
| from sklearn.datasets import fetch_20newsgroups
news = fetch_20newsgroups(subset='all')
print news.data[0]
|
上述代码得出该数据共有 18846 条新闻,但是这些文本数据既没有被设定特征,也没有数字化的亮度。因此,在交给朴素贝叶斯分类器学习之前,要对数据做进一步的处理。
20 类新闻文本数据分割
1
2
3
| from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(news.data,news.target,test_size=0.25,random_state=42)
|
文本转换为特征向量进行 TF 特征抽取
1
2
3
4
5
6
7
| from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer()
# 训练数据输入,并转换为特征向量
X_train = vec.fit_transform(X_train)
# 测试数据转换
X_test = vec.transform(X_test)
|
朴素贝叶斯分类器对文本数据进行类别预测
1
2
3
4
5
6
7
8
9
10
| from sklearn.naive_bayes import MultinomialNB
# 使用平滑处理初始化的朴素贝叶斯模型
mnb = MultinomialNB(alpha=1.0)
# 利用训练数据对模型参数进行估计
mnb.fit(X_train,y_train)
# 对测试验本进行类别预测。结果存储在变量y_predict中
y_predict = mnb.predict(X_test)
|
性能测试
朴素贝叶斯模型被广泛应用于海量互联网文本分类任务。由于其较强的特征条件独立假设,使得模型预测所需要估计的参数规模从幂指数量级想线性量级减少,极大的节约了内存消耗和计算时间。到那时,也正是受这种强假设的限制,模型训练时无法将各个特征之间的联系考量在内,使得该模型在其他数据特征关联性较强的分类任务上的性能表现不佳。
# 3.4 分类算法之逻辑回归
逻辑回归(Logistic Regression),简称 LR。它的特点是能够是我们的特征输入集合转化为 0 和 1 这两类的概率。一般来说,回归不用在分类问题上,因为回归是连续型模型,而且受噪声影响比较大。如果非要应用进入,可以使用逻辑回归。了解过线性回归之后再来看逻辑回归可以更好的理解。
优点:计算代价不高,易于理解和实现
缺点:容易欠拟合,分类精度不高
适用数据:数值型和标称型
# 逻辑回归
对于回归问题后面会介绍,Logistic 回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数 g(z) 将最为假设函数来预测。g(z) 可以将连续值映射到 0 和 1 上。Logistic 回归用来分类 0/1 问题,也就是预测结果属于 0 或者 1 的二值分类问题
映射函数为:
映射出来的效果如下如:
# sklearn.linear_model.LogisticRegression
逻辑回归类
1
2
3
4
5
6
7
8
| class sklearn.linear_model.LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='liblinear', max_iter=100, multi_class='ovr', verbose=0, warm_start=False, n_jobs=1)
"""
:param C: float,默认值:1.0
:param penalty: 特征选择的方式
:param tol: 公差停止标准
"""
|
1
2
3
4
5
6
7
8
9
10
11
| from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
from sklearn.linear_model import LogisticRegression
LR = LogisticRegression(C=1.0, penalty='l1', tol=0.01)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
LR.fit(X_train,y_train)
LR.predict(X_test)
LR.score(X_test,y_test)
0.96464646464646464
# c=100.0
0.96801346801346799
|
# 属性
coef_
决策功能的特征系数
Cs_
数组 C,即用于交叉验证的正则化参数值的倒数
# 特点分析
线性分类器可以说是最为基本和常用的机器学习模型。尽管其受限于数据特征与分类目标之间的线性假设,我们仍然可以在科学研究与工程实践中把线性分类器的表现性能作为基准。
# 3.5 逻辑回归算法案例分析
# 良/恶性乳腺癌肿瘤预测
原始数据的下载地址为:https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/
数据预处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import pandas as pd
import numpy as np
# 根据官方数据构建类别
column_names = ['Sample code number','Clump Thickness ','Uniformity of Cell Size','Uniformity of Cell Shape','Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli','Mitoses','Class'],
data = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/',names = column_names)
# 将?替换成标准缺失值表示
data = data.replace(to_replace='?',value = np.nan)
# 丢弃带有缺失值的数据(只要一个维度有缺失)
data = data.dropna(how='any')
data.shape
|
处理的缺失值后的样本共有 683 条,特征包括细胞厚度、细胞大小、形状等九个维度
准备训练测试数据
1
2
3
4
5
6
7
8
| from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(data[column_names[1:10]],data[column_names[10]],test_size=0.25,random_state=42)
# 查看训练和测试样本的数量和类别分布
y_train.value_counts()
y_test.value_counts()
|
使用逻辑回归进行良/恶性肿瘤预测任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# 标准化数据,保证每个维度的特征数据方差为1,均值为0。使得预测结果不会被某些维度过大的特征值而主导
ss = StandardScaler()
X_train = ss.fit_transform(X_train)
X_test = ss.transform(X_test)
# 初始化 LogisticRegression
lr = LogisticRegression(C=1.0, penalty='l1', tol=0.01)
# 跳用LogisticRegression中的fit函数/模块来训练模型参数
lr.fit(X_train,y_train)
lr_y_predict = lr.predict(X_test)
|
性能分析
1
2
3
4
5
6
| from sklearn.metrics import classification_report
# 利用逻辑斯蒂回归自带的评分函数score获得模型在测试集上的准确定结果
print '精确率为:',lr.score(X_test,y_test)
print classification_report(y_test,lr_y_predict,target_names = ['Benign','Maligant'])
|
# 3.6 分类器性能评估
在许多实际问题中,衡量分类器任务的成功程度是通过固定的性能指标来获取。一般最常见使用的是准确率,即预测结果正确的百分比。然而有时候,我们关注的是负样本是否被正确诊断出来。例如,关于肿瘤的的判定,需要更加关心多少恶性肿瘤被正确的诊断出来。也就是说,在二类分类任务下,预测结果 (Predicted Condition) 与正确标记 (True Condition) 之间存在四种不同的组合,构成混淆矩阵。
在二类问题中,如果将一个正例判为正例,那么就可以认为产生了一个真正例(True Positive,TP);如果对一个反例正确的判为反例,则认为产生了一个真反例(True Negative,TN)。相应地,两外两种情况则分别称为伪反例(False Negative,FN,也称)和伪正例(False Positive,TP),四种情况如下图:
在分类中,当某个类别的重要性高于其他类别时,我们就可以利用上述定义出多个逼错误率更好的新指标。第一个指标就是精确率(Precision),它等于 TP/(TP+FP),给出的是预测为正例的样本中占真实结果总数的比例。第二个指标是召回率(Recall)。它等于 TP/(TP+FN),给出的是预测为正例的真实正例占所有真实正例的比例。
那么除了正确率和精确率这两个指标之外,为了综合考量召回率和精确率,我们计算这两个指标的调和平均数,得到 F1 指标(F1 measure):
之所以使用调和平均数,是因为它除了具备平均功能外,还会对那些召回率和精确率更加接近的模型给予更高的分数;而这也是我们所希望的,因为那些召回率和精确率差距过大的学习模型,往往没有足够的使用价值。
sklearn.metrics.classification_report
sklearn 中 metrics 中提供了计算四个指标的模块,也就是 classification_report。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| classification_report(y_true, y_pred, labels=None, target_names=None, digits=2)
"""
计算分类指标
:param y_true:真实目标值
:param y_pred:分类器返回的估计值
:param target_names:可选的,计算与目标类别匹配的结果
:param digits:格式化输出浮点值的位数
:return :字符串,三个指标值
"""
|
我们通过一个例子来分析一下指标的结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 2]
y_pred = [0, 0, 2, 2, 1]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))
precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
avg / total 0.70 0.60 0.61 5
|
# 3.7 分类算法之决策树
决策树是一种基本的分类方法,当然也可以用于回归。我们一般只讨论用于分类的决策树。决策树模型呈树形结构。在分类问题中,表示基于特征对实例进行分类的过程,它可以认为是 if-then 规则的集合。在决策树的结构中,每一个实例都被一条路径或者一条规则所覆盖。通常决策树学习包括三个步骤:特征选择、决策树的生成和决策树的修剪
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理逻辑回归等不能解决的非线性特征数据
缺点:可能产生过度匹配问题
适用数据类型:数值型和标称型
# 特征选择
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率,如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的京都影响不大。通常特征选择的准则是信息增益,这是个数学概念。通过一个例子来了解特征选择的过程。
| ID | 年龄 | 有工作 | 有自己的房子 | 信贷情况 | 类别 |
|---|
| 1 | 青年 | 否 | 否 | 一般 | 否 |
| 2 | 青年 | 否 | 否 | 好 | 否 |
| 3 | 青年 | 是 | 否 | 好 | 是 |
| 4 | 青年 | 是 | 是 | 一般 | 是 |
| 5 | 青年 | 否 | 否 | 一般 | 否 |
| 6 | 中年 | 否 | 否 | 一般 | 否 |
| 7 | 中年 | 否 | 否 | 好 | 否 |
| 8 | 中年 | 是 | 是 | 好 | 是 |
| 9 | 中年 | 否 | 是 | 非常好 | 是 |
| 10 | 中年 | 否 | 是 | 非常好 | 是 |
| 11 | 老年 | 否 | 是 | 非常好 | 是 |
| 12 | 老年 | 否 | 是 | 好 | 是 |
| 13 | 老年 | 是 | 否 | 好 | 是 |
| 14 | 老年 | 是 | 否 | 非常好 | 是 |
| 15 | 老年 | 否 | 否 | 一般 | 否 |
我们希望通过所给的训练数据学习一个贷款申请的决策树,用以对文莱的贷款申请进行分类,即当新的客户提出贷款申请是,根据申请人的特征利用决策树决定是否批准贷款申请。特征选择其实是决定用那个特征来划分特征空间。下图中分别是按照年龄,还有是否有工作来划分得到不同的子节点
问题是究竟选择哪个特征更好些呢?那么直观上,如果一个特征具有更好的分类能力,是的各个自己在当前的条件下有最好的分类,那么就更应该选择这个特征。信息增益就能很好的表示这一直观的准则。这样得到的一棵决策树只用了两个特征就进行了判断:
通过信息增益生成的决策树结构,更加明显、快速的划分类别。下面介绍 scikit-learn 中 API 的使用
# 信息的度量和作用
我们常说信息有用,那么它的作用如何客观、定量地体现出来呢?信息用途的背后是否有理论基础呢?这个问题一直没有很好的回答,直到 1948 年,香农在他的论文“通信的数学原理”中提到了“信息熵”的概念,才解决了信息的度量问题,并量化出信息的作用。
一条信息的信息量与其不确定性有着直接的关系,比如我们要搞清一件非常不确定的事,就需要大量的信息。相反如果对某件事了解较多,则不需要太多的信息就能把它搞清楚 。所以从这个角度看,可以认为,信息量就等于不确定的多少。那么如何量化信息量的度量呢?2022 年举行世界杯,大家很关系谁是冠军。假如我错过了看比赛,赛后我问朋友 ,“谁是冠军”?他不愿意直接告诉我,让我每猜一次给他一块钱,他告诉我是否猜对了,那么我需要掏多少钱才能知道谁是冠军?我可以把球编上号,从 1 到 32,然后提问:冠 军在 1-16 号吗?依次询问,只需要五次,就可以知道结果。所以谁是世界杯冠军这条消息只值五块钱。当然香农不是用钱,而是用“比特”这个概念来度量信息量。一个比特是 一位二进制数,在计算机中一个字节是 8 比特。
那么如果说有一天有 64 支球队进行决赛阶段的比赛,那么“谁是世界杯冠军”的信息量就是 6 比特,因为要多猜一次,有的同学就会发现,信息量的比特数和所有可能情况的对数函数 log 有关,(log32=5,log64=6)
另外一方面你也会发现实际上我们不需要猜五次就能才出冠军,因为像西班牙、巴西、德国、意大利这样的球队夺得冠军的可能性比南非、尼日利亚等球队大得多,因此第一次猜测时不需要把 32 支球队等分成两个组,而可以把少数几支最有可能的球队分成一组,把其他球队分成一组。然后才冠军球队是否在那几支热门队中。这样,也许三次就猜出结果。因此,当每支球队夺冠的可能性不等时,“谁是世界杯冠军”的信息量比 5 比特少。香农指出,它的准确信息量应该是:
H = -(p1logp1 + p2logp2 + … + p32log32)
其中,p1…p32 为这三支球队夺冠的概率。H 的专业术语称之为信息熵,单位为比特,当这 32 支球队夺冠的几率相同时,对应的信息熵等于 5 比特,这个可以通过计算得出。有一个特性就是,5 比特是公式的最大值。那么信息熵(经验熵)的具体定义可以为如下:
# 信息增益
自古以来,信息和消除不确定性是相联系的。所以决策树的过程其实是在寻找某一个特征对整个分类结果的不确定减少的过程。那么这样就有一个概念叫做信息增益(information gain)。
那么信息增益表示得知特征 X 的信息而是的类 Y 的信息的不确定性减少的程度,所以我们对于选择特征进行分类的时候,当然选择信息增益较大的特征,这样具有较强的分类能力。特征 A 对训练数据集 D 的信息增益 g(D,A),定义为集合 D 的经验熵 H(D) 与特征 A 给定条件下 D 的经验条件熵 H(D|A) 之差,即公式为:
g(D,A)=H(D)−H(D∣A)
根据信息增益的准则的特征选择方法是:对于训练数据集 D,计算其每个特征的信息增益,并比较它们的阿笑,选择信息增益最大的特征
# 信息增益的计算
既然我们有了这两个公式,我们可以根据前面的是否通过贷款申请的例子来通过计算得出我们的决策特征顺序。那么我们首先计算总的经验熵为:
然后我们让 A1,A2,A3,A4A1,A2,A3,A4 分别表示年龄、有工作、有自己的房子和信贷情况 4 个特征,则计算出年龄的信息增益为:
同理其他的也可以计算出来,g(D,A2)=0.324,g(D,A3)=0.420,g(D,A4)=0.363,相比较来说其中特征 A3(有自己的房子)的信息增益最大,所以我们选择特征 A3 为最有特征
# sklearn.tree.DecisionTreeClassifier
sklearn.tree.DecisionTreeClassifier 是一个能对数据集进行多分类的类
1
2
3
4
5
6
| class sklearn.tree.DecisionTreeClassifier(criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_split=1e-07, class_weight=None, presort=False)
"""
:param max_depth:int或None,可选(默认=无)树的最大深度。如果没有,那么节点将被扩展,直到所有的叶子都是纯类,或者直到所有的叶子都包含少于min_samples_split样本
:param random_state:random_state是随机数生成器使用的种子
"""
|
首先我们导入类,以及数据集,还有将数据分成训练数据集和测试数据集两部分
1
2
3
4
5
6
7
8
9
| from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
estimator = DecisionTreeClassifier(max_leaf_nodes=3, random_state=0)
estimator.fit(X_train, y_train)
|
# Method
apply 返回每个样本被预测的叶子的索引
1
2
3
4
5
6
7
8
9
10
11
| estimator.apply(X)
array([ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
5, 5, 15, 5, 5, 5, 5, 5, 5, 10, 5, 5, 5, 5, 5, 10, 5,
5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 16, 16,
16, 16, 16, 16, 6, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16,
8, 16, 16, 16, 16, 16, 16, 14, 16, 16, 11, 16, 16, 16, 8, 8, 16,
16, 16, 14, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16, 16])
|
decision_path 返回树中的决策路径
1
| dp = estimator.decision_path(X_test)
|
**fit_transform(X,y=None,fit_params) 输入数据,然后转换
predict(X) 预测输入数据的类型,完整代码
1
2
3
4
5
6
7
8
| estimator.predict(X_test)
array([2, 1, 0, 2, 0, 2, 0, 1, 1, 1, 2, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0,
0, 1, 0, 0, 1, 1, 0, 2, 1, 0, 1, 2, 1, 0, 2])
print y_test
array([2, 1, 0, 2, 0, 2, 0, 1, 1, 1, 2, 1, 1, 1, 1, 0, 1, 1, 0, 0, 2, 1, 0,
0, 2, 0, 0, 1, 1, 0, 2, 1, 0, 2, 2, 1, 0, 1])
|
score(X,y,sample_weight=None) 返回给定测试数据的准确精度
1
2
3
| estimator.score(X_test,y_test)
0.89473684210526316
|
# 决策树本地保存
sklearn.tree.export_graphviz() 该函数能够导出 DOT 格式
1
2
3
4
5
6
| from sklearn.datasets import load_iris
from sklearn import tree
clf = tree.DecisionTreeClassifier()
iris = load_iris()
clf = clf.fit(iris.data, iris.target)
tree.export_graphviz(clf,out_file='tree.dot')
|
那么有了 tree.dot 文件之后,我们可以通过命令转换为 png 或者 pdf 格式,首先得安装 graphviz
1
2
| ubuntu:sudo apt-get install graphviz
Mac:brew install graphviz
|
然后我们运行这个命令
1
2
| $ dot -Tps tree.dot -o tree.ps
$ dot -Tpng tree.dot -o tree.png
|
或者,如果我们安装了 Python 模块 pydotplus,我们可以直接在 Python 中生成 PDF 文件,通过 pip install pydotplus,然后运行
1
2
3
4
| import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")
|
查看决策树结构图片,这个结果是经过决策树学习的三个步骤之后形成的。当作了解
扩展:所有各种决策树算法是什么,它们之间有什么不同?哪一个在 scikit-learn 中实现?
ID3 — 信息增益 最大的准则
C4.5 — 信息增益比 最大的准则
CART 回归树: 平方误差 最小 分类树: 基尼系数 最小的准则 在 sklearn 中可以选择划分的原则
# 决策树优缺点分析
决策树的一些优点是:
- 简单的理解和解释。树木可视化。
- 需要很少的数据准备。其他技术通常需要数据归一化,需要创建虚拟变量,并删除空值。但请注意,此模块不支持缺少值。
- 使用树的成本(即,预测数据)在用于训练树的数据点的数量上是对数的。
决策树的缺点包括:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树。这被称为过拟合。修剪(目前不支持)的机制,设置叶节点所需的最小采样数或设置树的最大深度是避免此问题的必要条件。
- 决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成。通过使用合奏中的决策树来减轻这个问题。
# 3.8 集成方法(分类)之随机森林
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。利用相同的训练数搭建多个独立的分类模型,然后通过投票的方式,以少数服从多数的原则作出最终的分类决策。例如, 如果你训练了 5 个树, 其中有 4 个树的结果是 True, 1 个数的结果是 False, 那么最终结果会是 True.
在前面的决策当中我们提到,一个标准的决策树会根据每维特征对预测结果的影响程度进行排序,进而决定不同的特征从上至下构建分裂节点的顺序,如此以来,所有在随机森林中的决策树都会受这一策略影响而构建的完全一致,从而丧失的多样性。所以在随机森林分类器的构建过程中,每一棵决策树都会放弃这一固定的排序算法,转而随机选取特征。
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
定义:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
优点:
- 在当前所有算法中,具有极好的准确率
- 能够有效地运行在大数据集上
- 能够处理具有高维特征的输入样本,而且不需要降维
- 能够评估各个特征在分类问题上的重要性
- 对于缺省值问题也能够获得很好得结果
# 学习算法
根据下列算法而建造每棵树:
- 用 N 来表示训练用例(样本)的个数,M 表示特征数目。
- 输入特征数目 m,用于确定决策树上一个节点的决策结果;其中 m 应远小于 M。
- 从 N 个训练用例(样本)中以有放回抽样的方式,取样 N 次,形成一个训练集(即 bootstrap 取样),并用未抽到的用例(样本)作预测,评估其误差。
- 对于每一个节点,随机选择 m 个特征,决策树上每个节点的决定都是基于这些特征确定的。根据这 m 个特征,计算其最佳的分裂方式。
# sklearn.ensemble,集成方法模块
sklearn.ensemble 提供了准确性更加好的集成方法,里面包含了主要的 RandomForestClassifier(随机森林) 方法。
1
2
3
4
5
6
7
8
9
10
11
| class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, oob_score=False, n_jobs=1, random_state=None)
"""
:param n_estimators:integer,optional(default = 10) 森林里的树木数量。
:param criteria:string,可选(default =“gini”)分割特征的测量方法
:param max_depth:integer或None,可选(默认=无)树的最大深度
:param bootstrap:boolean,optional(default = True)是否在构建树时使用自举样本。
"""
|
# 属性
- classes_:shape = [n_classes] 的数组或这样的数组的列表,类标签(单输出问题)或类标签数组列表(多输出问题)。
- featureimportances:array = [n_features] 的数组, 特征重要性(越高,功能越重要)。
# 方法
- fit(X,y [,sample_weight]) 从训练集(X,Y)构建一棵树林。
- predict(X) 预测 X 的类
- score(X,y [,sample_weight]) 返回给定测试数据和标签的平均精度。
- decision_path(X) 返回森林中的决策路径
# 泰坦尼克号乘客数据案例
这里我们通过决策树和随机森林对这个数据进行一个分类,判断乘客的生还。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| import pandas as pd
import sklearn
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
#选取一些特征作为我们划分的依据
x = titanicspan>&
y = titanic['survived']
# 填充缺失值
x['age'].fillna(x['age'].mean(), inplace=True)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
dt = DictVectorizer(sparse=False)
print(x_train.to_dict(orient="record"))
# 按行,样本名字为键,列名也为键,[{"1":1,"2":2,"3":3}]
x_train = dt.fit_transform(x_train.to_dict(orient="record"))
x_test = dt.fit_transform(x_test.to_dict(orient="record"))
# 使用决策树
dtc = DecisionTreeClassifier()
dtc.fit(x_train, y_train)
dt_predict = dtc.predict(x_test)
print(dtc.score(x_test, y_test))
print(classification_report(y_test, dt_predict, target_names=["died", "survived"]))
# 使用随机森林
rfc = RandomForestClassifier()
rfc.fit(x_train, y_train)
rfc_y_predict = rfc.predict(x_test)
print(rfc.score(x_test, y_test))
print(classification_report(y_test, rfc_y_predict, target_names=["died", "survived"]))
|
# 总结
# 4. 回归算法
回归是统计学中最有力的工具之一。机器学习监督学习算法分为分类算法和回归算法两种,其实就是根据类别标签分布类型为离散型、连续性而定义的。回归算法用于连续型分布预测,针对的是数值型的样本,使用回归,可以在给定输入的时候预测出一个数值,这是对分类方法的提升,因为这样可以预测连续型数据而不仅仅是离散的类别标签。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。那么什么是线性关系和非线性关系?
比如说在房价上,房子的面积和房子的价格有着明显的关系。那么 X=房间大小,Y=房价,那么在坐标系中可以看到这些点:
那么通过一条直线把这个关系描述出来,叫线性关系。
如果是一条曲线,那么叫非线性关系
那么回归的目的就是建立一个回归方程(函数)用来预测目标值,回归的求解就是求这个回归方程的回归系数。
# 4.1 回归算法之线性回归
线性回归的定义是:目标值预期是输入变量的线性组合。线性模型形式简单、易于建模,但却蕴含着机器学习中一些重要的基本思想。线性回归,是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。
优点:结果易于理解,计算不复杂
缺点:对非线性的数据拟合不好
适用数据类型:数值型和标称型
对于单变量线性回归,例如:前面房价例子中房子的大小预测房子的价格。f(x) = w1*x+w0,这样通过主要参数 w1 就可以得出预测的值。
通用公式为:
那么对于多变量回归,例如:瓜的好坏程度 f(x) = w0+0.2* 色泽 +0.5* 根蒂 +0.3* 敲声,得出的值来判断一个瓜的好与不好的程度。
通用公式为:
线性模型中的向量 W 值,客观的表达了各属性在预测中的重要性,因此线性模型有很好的解释性。对于这种“多特征预测”也就是(多元线性回归),那么线性回归就是在这个基础上得到这些 W 的值,然后以这些值来建立模型,预测测试数据。简单的来说就是学得一个线性模型以尽可能准确的预测实值输出标记。
那么如果对于多变量线性回归来说我们可以通过向量的方式来表示 W 值与特征 X 值之间的关系:
两向量相乘,结果为一个整数是估计值,其中所有特征集合的第一个特征值 x0=1,那么我们可以通过通用的向量公式来表示线性模型:
一个列向量的转置与特征的乘积,得出我们预测的结果,但是显然我们这个模型得到的结果可定会有误差,如下图所示:
# 损失函数
损失函数是一个贯穿整个机器学习重要的一个概念,大部分机器学习算法都会有误差,我们得通过显性的公式来描述这个误差,并且将这个误差优化到最小值。
对于线性回归模型,将模型与数据点之间的距离差之和做为衡量匹配好坏的标准,误差越小,匹配程度越大。我们要找的模型就是需要将 f(x) 和我们的真实值之间最相似的状态。于是我们就有了误差公式,模型与数据差的平方和最小:
上面公式定义了所有的误差和,那么现在需要使这个值最小?那么有两种方法,一种使用梯度下降算法,另一种使正规方程解法(只适用于简单的线性回归)。
# 梯度下降算法
上面误差公式是一个通式,我们取两个单个变量来求最小值,误差和可以表示为:
可以通过调整不同的 w1 和 w0 的值,就能使误差不断变化,而当你找到这个公式的最小值时,你就能得到最好的 w1,w0 而这对 (w1,w0) 就是能最好描述你数据关系的模型参数。
怎么找 cost(w0+w1x1) 的最小? cost(w0+w1x1) 的图像其实像一个山谷一样,有一个最低点。找这个最低点的办法就是,先随便找一个点 (w1=5, w0=4), 然后 沿着这个碗下降的方向找,最后就能找到山谷的最低点。
所以得出
,那么这个过程是按照某一点在 w1 上的偏导数下降寻找最低点。当然在进行移动的时候也需要考虑,每次移动的速度,也就是αα的值,这个值也叫做(学习率),如下式:
这样就能求出 w0,w1 的值,当然你这个过程是不断的进行迭代求出来,通过交叉验证方法即可。
# LinearRegression
# sklearn.linear_model.LinearRegression
1
2
3
4
5
6
7
8
| class LinearRegression(fit_intercept = True,normalize = False,copy_X = True,n_jobs = 1)
"""
:param normalize:如果设置为True时,数据进行标准化。请在使用normalize = False的估计器调时用fit之前使用preprocessing.StandardScaler
:param copy_X:boolean,可选,默认为True,如果为True,则X将被复制
:param n_jobs:int,可选,默认1。用于计算的CPU核数
"""
|
实例代码:
1
2
| from sklearn.linear_model import LinearRegression
reg = LinearRegression()
|
# 方法
fit(X,y,sample_weight = None)
使用 X 作为训练数据拟合模型,y 作为 X 的类别值。X,y 为数组或者矩阵
1
| reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
|
predict(X)
预测提供的数据对应的结果
1
2
3
| reg.predict(span>)
array([ 3.])
|
# 属性
coef_
表示回归系数 w=(w1,w2….)
1
2
3
| reg.coef_
array([ 0.5, 0.5])
|
intercept_ 表示 w0
# 加入交叉验证
前面我们已经提到了模型的交叉验证,那么我们这个自己去建立数据集,然后通过线性回归的交叉验证得到模型。由于 sklearn 中另外两种回归岭回归、lasso 回归都本省提供了回归 CV 方法,比如 linear_model.Lasso,交叉验证 linear_model.LassoCV;linear_model.Ridge,交叉验证 linear_model.RidgeCV。所以我们需要通过前面的 cross_validation 提供的方法进行 k- 折交叉验证。
1
2
3
4
5
6
7
8
9
| from sklearn.datasets.samples_generator import make_regression
from sklearn.model_selection import cross_val_score
from sklearn import linear_model
import matplotlib.pyplot as plt
lr = linear_model.LinearRegression()
X, y = make_regression(n_samples=200, n_features=5000, random_state=0)
result = cross_val_score(lr, X, y)
print result
|
# 4.2 线性回归案例分析
# 波士顿房价预测
使用 scikit-learn 中内置的回归模型对“美国波士顿房价”数据进行预测。对于一些比赛数据,可以从 kaggle 官网上获取,网址:https://www.kaggle.com/datasets
1.美国波士顿地区房价数据描述
1
2
3
4
5
| from sklearn.datasets import load_boston
boston = load_boston()
print boston.DESCR
|
2.波士顿地区房价数据分割
1
2
3
4
5
6
| from sklearn.cross_validation import train_test_split
import numpy as np
X = boston.data
y = boston.target
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=33,test_size = 0.25)
|
3.训练与测试数据标准化处理
1
2
3
4
5
6
7
8
| from sklearn.preprocessing import StandardScaler
ss_X = StandardScaler()
ss_y = StandardScaler()
X_train = ss_X.fit_transform(X_train)
X_test = ss_X.transform(X_test)
y_train = ss_X.fit_transform(y_train)
X_train = ss_X.transform(y_test)
|
4.使用最简单的线性回归模型 LinearRegression 和梯度下降估计 SGDRegressor 对房价进行预测
1
2
3
4
5
6
7
8
9
| from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train,y_train)
lr_y_predict = lr.predict(X_test)
from sklearn.linear_model import SGDRegressor
sgdr = SGDRegressor()
sgdr.fit(X_train,y_train)
sgdr_y_predict = sgdr.predict(X_test)
|
5.性能评测
对于不同的类别预测,我们不能苛刻的要求回归预测的数值结果要严格的与真实值相同。一般情况下,我们希望衡量预测值与真实值之间的差距。因此,可以测评函数进行评价。其中最为直观的评价指标均方误差 (Mean Squared Error)MSE,因为这也是线性回归模型所要优化的目标。
MSE 的计算方法如式:
MSE=1m∑i=1m(yi−y¯)2MSE=m1∑i=1m(y**i−y¯)2
使用 MSE 评价机制对两种模型的回归性能作出评价
1
2
3
4
| from sklearn.metrics import mean_squared_error
print '线性回归模型的均方误差为:',mean_squared_error(ss_y.inverse_transform(y_test),ss_y.inverse_tranform(lr_y_predict))
print '梯度下降模型的均方误差为:',mean_squared_error(ss_y.inverse_transform(y_test),ss_y.inverse_tranform(sgdr_y_predict))
|
通过这一比较发现,使用梯度下降估计参数的方法在性能表现上不及使用解析方法的 LinearRegression,但是如果面对训练数据规模十分庞大的任务,随即梯度法不论是在分类还是回归问题上都表现的十分高效,可以在不损失过多性能的前提下,节省大量计算时间。根据 Scikit-learn 光网的建议,如果数据规模超过 10 万,推荐使用随机梯度法估计参数模型。
注意:线性回归器是最为简单、易用的回归模型。正式因为其对特征与回归目标之间的线性假设,从某种程度上说也局限了其应用范围。特别是,现实生活中的许多实例数据的各种特征与回归目标之间,绝大多数不能保证严格的线性关系。尽管如此,在不清楚特征之间关系的前提下,我们仍然可以使用线性回归模型作为大多数数据分析的基线系统。
完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
| from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_boston
from sklearn.cross_validation import train_test_split
from sklearn.metrics import mean_squared_error,classification_report
from sklearn.cluster import KMeans
def linearmodel():
"""
线性回归对波士顿数据集处理
:return: None
"""
# 1、加载数据集
ld = load_boston()
x_train,x_test,y_train,y_test = train_test_split(ld.data,ld.target,test_size=0.25)
# 2、标准化处理
# 特征值处理
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
# 目标值进行处理
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
# 3、估计器流程
# LinearRegression
lr = LinearRegression()
lr.fit(x_train,y_train)
# print(lr.coef_)
y_lr_predict = lr.predict(x_test)
y_lr_predict = std_y.inverse_transform(y_lr_predict)
print("Lr预测值:",y_lr_predict)
# SGDRegressor
sgd = SGDRegressor()
sgd.fit(x_train,y_train)
# print(sgd.coef_)
y_sgd_predict = sgd.predict(x_test)
y_sgd_predict = std_y.inverse_transform(y_sgd_predict)
print("SGD预测值:",y_sgd_predict)
# 带有正则化的岭回归
rd = Ridge(alpha=0.01)
rd.fit(x_train,y_train)
y_rd_predict = rd.predict(x_test)
y_rd_predict = std_y.inverse_transform(y_rd_predict)
print(rd.coef_)
# 两种模型评估结果
print("lr的均方误差为:",mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
print("SGD的均方误差为:",mean_squared_error(std_y.inverse_transform(y_test),y_sgd_predict))
print("Ridge的均方误差为:",mean_squared_error(std_y.inverse_transform(y_test),y_rd_predict))
return None
|
# 4.3 欠拟合与过拟合
机器学习中的泛化,泛化即是,模型学习到的概念在它处于学习的过程中时模型没有遇见过的样本时候的表现。在机器学习领域中,当我们讨论一个机器学习模型学习和泛化的好坏时,我们通常使用术语:过拟合和欠拟合。我们知道模型训练和测试的时候有两套数据,训练集和测试集。在对训练数据进行拟合时,需要照顾到每个点,而其中有一些噪点,当某个模型过度的学习训练数据中的细节和噪音,以至于模型在新的数据上表现很差,这样的话模型容易复杂,拟合程度较高,造成过拟合。而相反如果值描绘了一部分数据那么模型复杂度过于简单,欠拟合指的是模型在训练和预测时表现都不好的情况,称为欠拟合。
我们来看一下线性回归中拟合的几种情况图示:
# 解决过拟合的方法
在线性回归中,对于特征集过小的情况,容易造成欠拟合(underfitting),对于特征集过大的情况,容易造成过拟合(overfitting)。针对这两种情况有了更好的解决办法
# 欠拟合
欠拟合指的是模型在训练和预测时表现都不好的情况,欠拟合通常不被讨论,因为给定一个评估模型表现的指标的情况下,欠拟合很容易被发现。矫正方法是继续学习并且试着更换机器学习算法。
# 过拟合
对于过拟合,特征集合数目过多,我们需要做的是尽量不让回归系数数量变多,对拟合(损失函数)加以限制。
(1)当然解决过拟合的问题可以减少特征数,显然这只是权宜之计,因为特征意味着信息,放弃特征也就等同于丢弃信息,要知道,特征的获取往往也是艰苦卓绝的。
(2)引入了 正则化 概念。
直观上来看,如果我们想要解决上面回归中的过拟合问题,我们最好就要消除 x3*x*3 和 x4*x*4 的影响,也就是想让θ3,θ4*θ*3,*θ*4 都等于 0,一个简单的方法就是我们对θ3,θ4*θ*3,*θ*4 进行惩罚,增加一个很大的系数,这样在优化的过程中就会使这两个参数为零。
##4.4 回归算法之岭回归
具有 L2 正则化的线性最小二乘法。岭回归是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法。当数据集中存在共线性的时候,岭回归就会有用。
# sklearn.linear_model.Ridge
1
2
3
4
5
6
7
| class sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True, normalize=False, copy_X=True, max_iter=None, tol=0.001, solver='auto', random_state=None)**
"""
:param alpha:float类型,正规化的程度
"""
from sklearn.linear_model import Ridge
clf = Ridge(alpha=1.0)
clf.fit([[0, 0], [0, 0], [1, 1]], [0, .1, 1]))
|
# 方法
score(X, y, sample_weight=None)
# 属性
coef_
1
2
| clf.coef_
array([ 0.34545455, 0.34545455])
|
intercept_
1
2
| clf.intercept_
0.13636...
|
# 案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
| def linearmodel():
"""
线性回归对波士顿数据集处理
:return: None
"""
# 1、加载数据集
ld = load_boston()
x_train,x_test,y_train,y_test = train_test_split(ld.data,ld.target,test_size=0.25)
# 2、标准化处理
# 特征值处理
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
# 目标值进行处理
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train)
y_test = std_y.transform(y_test)
# 3、估计器流程
# LinearRegression
lr = LinearRegression()
lr.fit(x_train,y_train)
# print(lr.coef_)
y_lr_predict = lr.predict(x_test)
y_lr_predict = std_y.inverse_transform(y_lr_predict)
print("Lr预测值:",y_lr_predict)
# SGDRegressor
sgd = SGDRegressor()
sgd.fit(x_train,y_train)
# print(sgd.coef_)
y_sgd_predict = sgd.predict(x_test)
y_sgd_predict = std_y.inverse_transform(y_sgd_predict)
print("SGD预测值:",y_sgd_predict)
# 带有正则化的岭回归
rd = Ridge(alpha=0.01)
rd.fit(x_train,y_train)
y_rd_predict = rd.predict(x_test)
y_rd_predict = std_y.inverse_transform(y_rd_predict)
print(rd.coef_)
# 两种模型评估结果
print("lr的均方误差为:",mean_squared_error(std_y.inverse_transform(y_test),y_lr_predict))
print("SGD的均方误差为:",mean_squared_error(std_y.inverse_transform(y_test),y_sgd_predict))
print("Ridge的均方误差为:",mean_squared_error(std_y.inverse_transform(y_test),y_rd_predict))
return None
|
# 5. 非监督学习
从本节开始,将正式进入到无监督学习(Unsupervised Learning)部分。无监督学习,顾名思义,就是不受监督的学习,一种自由的学习方式。该学习方式不需要先验知识进行指导,而是不断地自我认知,自我巩固,最后进行自我归纳,在机器学习中,无监督学习可以被简单理解为不为训练集提供对应的类别标识(label),其与有监督学习的对比如下: 有监督学习(Supervised Learning)下的训练集:
(x(1),y(1)),(x(2),y2)(x(1),y(1)),(x(2),y2)
无监督学习(Unsupervised Learning)下的训练集:
(x(1)),(x(2)),(x(3))(x(1)),(x(2)),(x(3))
在有监督学习中,我们把对样本进行分类的过程称之为分类(Classification),而在无监督学习中,我们将物体被划分到不同集合的过程称之为聚类(Clustering)
##5.1 非监督学习之 k-means
K-means 通常被称为劳埃德算法,这在数据聚类中是最经典的,也是相对容易理解的模型。算法执行的过程分为 4 个阶段。
- 1.首先,随机设 K 个特征空间内的点作为初始的聚类中心。
- 2.然后,对于根据每个数据的特征向量,从 K 个聚类中心中寻找距离最近的一个,并且把该数据标记为这个聚类中心。
- 3.接着,在所有的数据都被标记过聚类中心之后,根据这些数据新分配的类簇,通过取分配给每个先前质心的所有样本的平均值来创建新的质心重,新对 K 个聚类中心做计算。
- 4.最后,计算旧和新质心之间的差异,如果所有的数据点从属的聚类中心与上一次的分配的类簇没有变化,那么迭代就可以停止,否则回到步骤 2 继续循环。
K 均值等于具有小的全对称协方差矩阵的期望最大化算法。
# sklearn.cluster.KMeans
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| class sklearn.cluster.KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto')
"""
:param n_clusters:要形成的聚类数以及生成的质心数
:param init:初始化方法,默认为'k-means ++',以智能方式选择k-均值聚类的初始聚类中心,以加速收敛;random,从初始质心数据中随机选择k个观察值(行
:param n_init:int,默认值:10使用不同质心种子运行k-means算法的时间。最终结果将是n_init连续运行在惯性方面的最佳输出。
:param n_jobs:int用于计算的作业数量。这可以通过并行计算每个运行的n_init。如果-1使用所有CPU。如果给出1,则不使用任何并行计算代码,这对调试很有用。对于-1以下的n_jobs,使用(n_cpus + 1 + n_jobs)。因此,对于n_jobs = -2,所有CPU都使用一个。
:param random_state:随机数种子,默认为全局numpy随机数生成器
"""
from sklearn.cluster import KMeans
import numpy as np
X = np.array([[1, 2], [1, 4], [1, 0],[4, 2], [4, 4], [4, 0]])
kmeans = KMeans(n_clusters=2, random_state=0)
|
# 方法
fit(X,y=None)
使用 X 作为训练数据拟合模型
predict(X)
预测新的数据所在的类别
1
2
| kmeans.predict([[0, 0], [4, 4]])
array([0, 1], dtype=int32)
|
# 属性
cluster*centers*
集群中心的点坐标
1
2
3
| kmeans.cluster_centers_
array([[ 1., 2.],
[ 4., 2.]])
|
labels_
每个点的类别
# K-means ++
# 手写数字数据上 K-Means 聚类的演示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| from sklearn.metrics import silhouette_score
from sklearn.cluster import KMeans
def kmeans():
"""
手写数字聚类过程
:return: None
"""
# 加载数据
ld = load_digits()
print(ld.target[:20])
# 聚类
km = KMeans(n_clusters=810)
km.fit_transform(ld.data)
print(km.labels_[:20])
print(silhouette_score(ld.data,km.labels_))
return None
if __name__=="__main__":
kmeans()
|
6fcc8243aa27f35e8c359944fe365cdac20d964f:Notes/Python/ML.md